Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
A post on Medium was shared with me by a member of my channel. A team went all in on event-driven architecture, and now they feel like they can’t debug anything. I get it, debugging event-driven systems can seem challenging.
But it’s not directly because of event-driven architecture. It’s because of their misunderstanding of it and how they were applying it.
So let’s break down the five pain points they had, why they had that pain, and how you can avoid it.
YouTube
Check out my YouTube channel, where I post all kinds of content on Software Architecture & Design, including this video showing everything in this post.
Where They Started
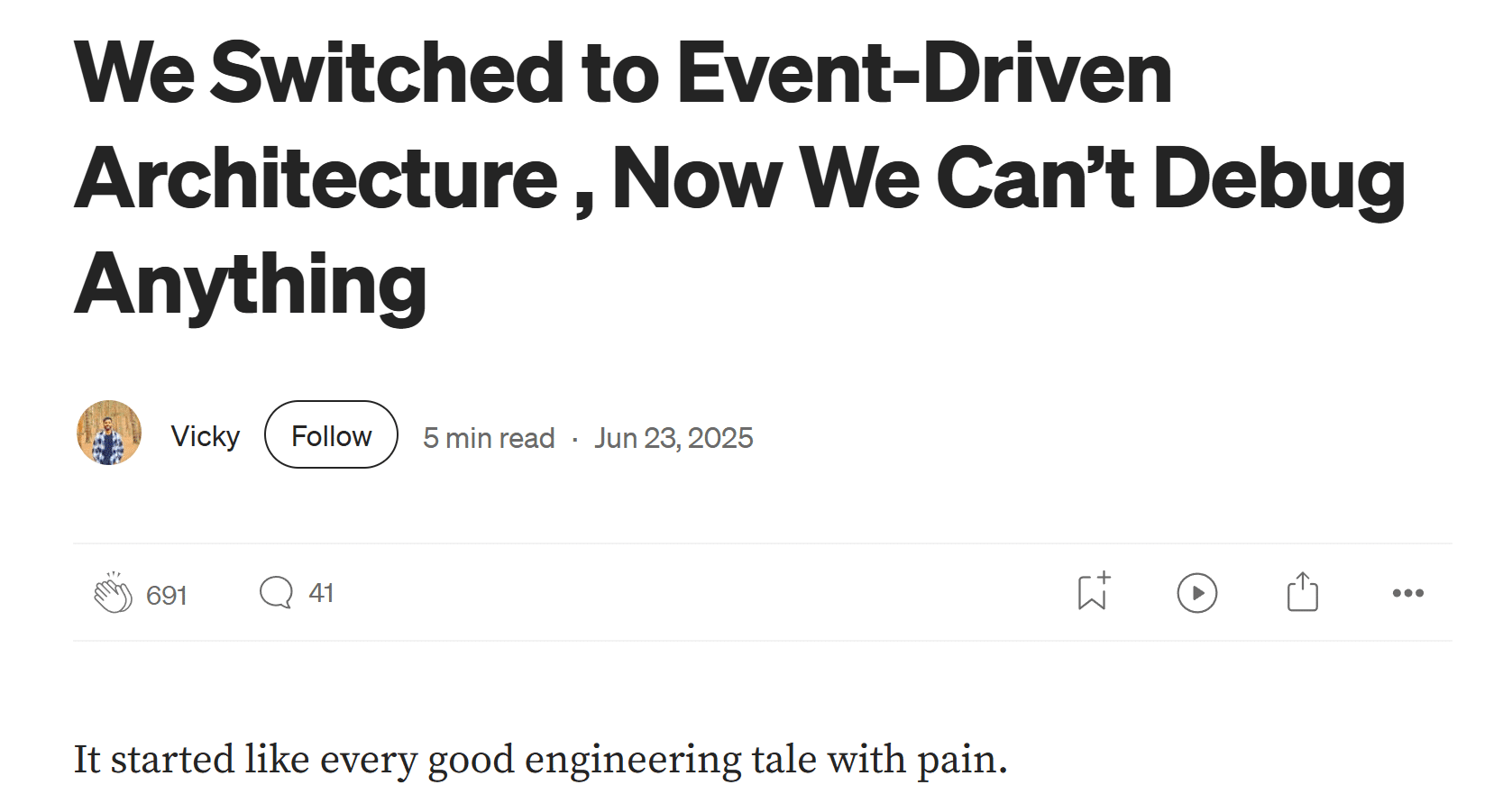
They started with what they called a REST based system, which really just means HTTP in most cases. They had services calling other services.
A client would make a request to Service A. Maybe Service A hits its database. Then Service A calls Service B to do something external. Then Service A calls Service C, which likely has its own database. Maybe Service C calls Service D, and eventually everything unwinds back to return a response to the client.
If that sounds like a disaster, well, it was.
They described it as a spaghetti mess of cascading HTTP calls, versioning nightmares between contracts across services, and a brittle orchestration layer.
That pain is real. But moving to events does not automatically fix it. In some cases, it just moves the confusion somewhere else.
Problem 1: Tracing Ended at Kafka
The first problem was tracing, specifically in an asynchronous workflow.
In their existing HTTP based system, they had something like this: the front end called the ordering service, the ordering service called the payment service, the payment service called the email service, and with OpenTelemetry and something like Zipkin or Jaeger, they could see that full flow.
With Kafka, however, they said that visibility completely broke. The order service produced an event, then the payment service, email service, inventory service, and other services listened to specific topics. But now they could not see what was actually happening as part of the workflow.
And yes, 100%, this is a pain.
You need good visibility and good tracing in any distributed application. Absolutely.
However, OpenTelemetry works just as well in an asynchronous system as it does in a synchronous system using HTTP between services. This should not be an unsolved problem.
To me, this sounds like a tooling problem.
They likely went from a more mature web framework where tracing just worked out of the box, to using Kafka or another messaging tool where they did not have the same level of instrumentation wired up.
I see this often when teams use the SDKs directly for whatever messaging system, event log, or message broker they’re using, rather than leveraging a messaging library that has tracing built in.
This is a solved problem. It just might not be solved in the tooling they chose, or in how they implemented it.
Problem 2: Dead Letter Queues Became Garbage Dumps
The second problem was that dead letter queues turned into garbage dumps.
They sound helpful. A way to isolate failed events. But in reality, they became a graveyard of mystery failures.
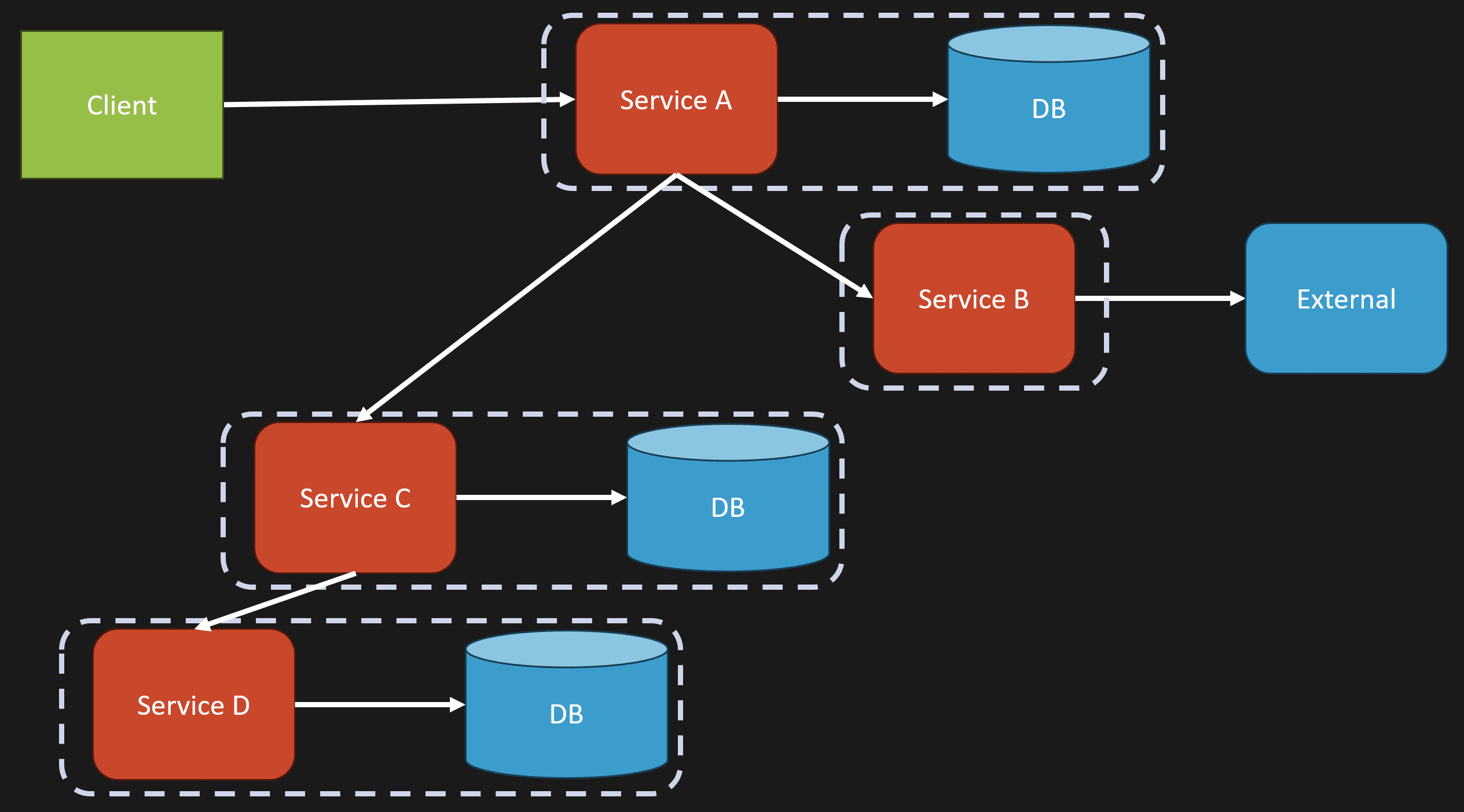
Dead letter queues are great, but they are just storage.
Imagine you have a queue and a consumer picking up messages. That consumer starts processing a message and needs to call some external service. That external service is failing. So you have some kind of backoff and retry. It keeps failing. Eventually, you put that message into a dead letter queue.
Later on, maybe manually, you pick that message back up and retry processing it.
That’s fine. But a dead letter queue without any way to inspect the message, replay the message, or see what errors and exceptions happened while processing the message is just a black hole.
It’s not useful by itself.
You need visibility into why the message is failing. You need to correlate the message with the actual error or exception that occurred.
Do you need to fix something in your code? Is it a poison message that is never going to work? Was there a transient failure when calling an external service, and if you call it now, it will succeed?
You need visibility into the failure and the message itself. Without that, a dead letter queue is just a place where problems go to be forgotten.
Problem 3: Fire and Forget Equals Debug and Regret
I liked this title from the post: “Fire and forget equals debug and regret.”
They made an analogy that REST is like ordering at a restaurant. You place an order and wait for confirmation.
Uh, you sure about that?
I often use a restaurant to explain asynchronous workflows, but in the opposite way.
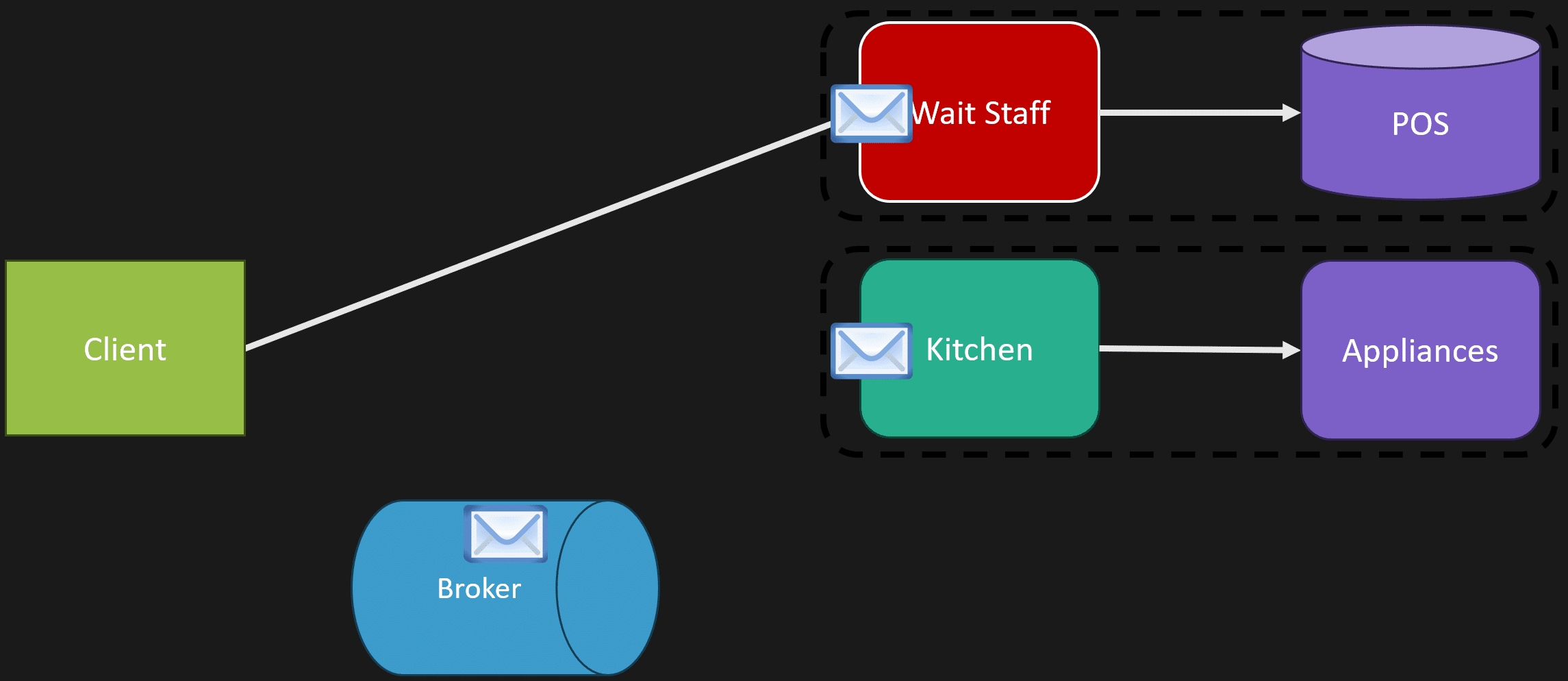
You arrive at a restaurant and someone greets you and seats you at a table. They don’t stand there and wait for you to order. They go back and perform another action, like greeting somebody else and seating another table.
The wait staff takes your order and puts it into a point of sale system so the kitchen understands there is something they need to do. The kitchen picks that up asynchronously and starts cooking your meal.
When the order is ready, there is probably another message to let the wait staff, or whoever has that role, know that the order is up and needs to be brought back to the customer.
It’s full of asynchrony. You just need to embrace it properly.
The biggest red flag in their post was very telling, because I see this over and over again. They were forcing everything to be an event and everything to be asynchronous.
It does not all need to be events.
They described it like throwing a note into a room and hoping somebody reads it. But that’s not really the point of events. What they’re describing is publish and subscribe, and even then, they’re missing the important distinction.
Events are facts. Something happened.
If you publish an event, you as the producer do not care if there are any consumers. There might be zero consumers. There might be a thousand. You don’t care.
You also don’t care if a downstream service did its job. That’s not the point of an event. You’re not asking another service to do something. You’re saying that something already happened.
That’s where commands and events are different.
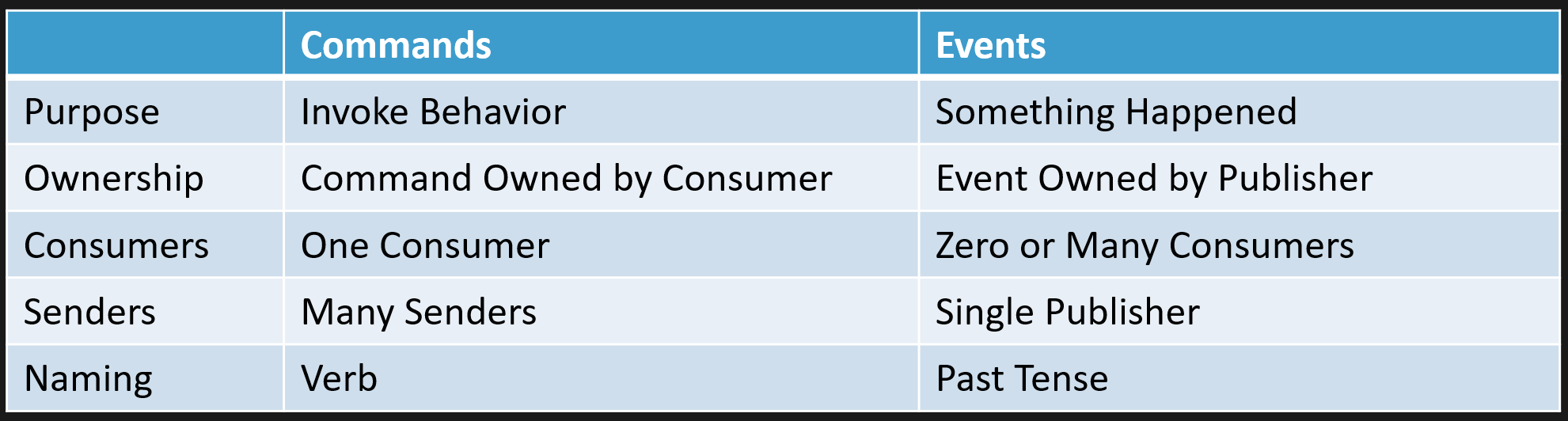
Commands and Events Are Not the Same Thing
Commands are about invoking behavior. They are owned by the consumer because there should be a single boundary responsible for handling that command.
There could be many different senders, depending on how you view your boundaries, but the command is handled by one consumer. Commands are named with verbs because they represent actions you want to invoke.
Events are totally different.
Events are facts. Something happened. You are notifying some other part of your system that this thing occurred.
Events are owned by whoever publishes them, because the event occurred inside that specific boundary. There should only be one publisher of that event. For consumers, there may be none, or there may be many.
Events are named in the past tense because they represent something that has already happened.
Commands and events have different utility. They are very different things.
Not everything needs to be asynchronous, just like not everything needs to be an event. Some things are naturally synchronous, like queries.
In their original HTTP system, they were calling different services to perform different actions. Of course those calls were synchronous. The mistake is assuming the fix is to turn all of that into events.
You have to understand what can be fire and forget and what is not best served that way because you immediately need a response.
There is also the option of doing asynchronous request reply when you need it.
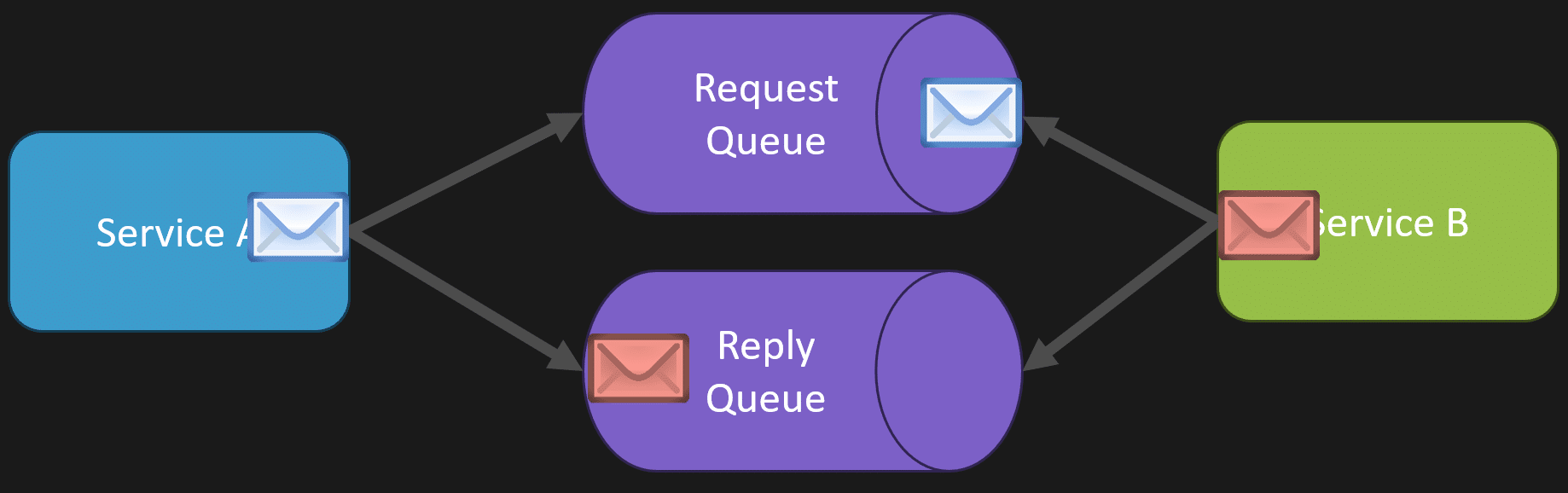
The way that works is you have a separate reply queue. You make a request where you need to know the response. Did it succeed? What was the outcome of that processing?
Service B processes the message. Once it completes, it sends a reply message to a separate queue that the original service can consume. That original service can then correlate the reply back to the original message and understand the outcome.
The author of the post mentioned they did this, except they seemed to do it all the time, which they probably didn’t need to.
Again, it comes back to understanding the interaction you actually need.
Problem 4: Eventual Consistency Is Like Eventual Accountability
Another title I loved from their post: “Eventual consistency is like eventual accountability.”
Let’s say an order flows through four services.
The order is placed. Inventory is reduced. Payment is charged. A confirmation email is sent.
If any step fails, you need to compensate.
Yes. Absolutely.
If payment fails, maybe you need to release the inventory. If something else fails, maybe you need to refund the payment or prevent the confirmation email from being sent.
This is a real problem. Coordinating what happens next when part of a workflow fails is not simple.
In an asynchronous world, the saga pattern is often the solution to this. It helps coordinate a long running business process and track what has completed, what has failed, and what compensating action needs to happen next.
But here’s the thing: this is not automatically easier in a synchronous world.
Think about a long procedural codebase full of nested try catch blocks calling different services. If this call succeeds but the next one fails, then do this. If that fails, do something else. Now compensate for the previous thing. Now handle the failure of the compensation.
That can become a nested mess too.
The benefit of doing this asynchronously is that you can have dead letter queues, visibility into what happened, and state behind the saga that tells you whether the process is complete or not.
But again, we come back to visibility and tooling.
If you don’t have visibility, you’re going to feel lost no matter what communication style you picked.
Problem 5: Testing Became a Nightmare
The fifth problem was testing.
They said unit tests were fine, but integration tests became a nightmare. Now they needed to spin up embedded Kafka, mock consumers and producers, and wait for asynchronous side effects.
That pain usually comes from trying to test everything across boundaries.
Remember, events are contracts. They are not conversations. They do not go both ways.
That is the distinction again between events and commands. Are you trying to invoke something, or are you trying to tell some other part of your system that something happened?
From the producer’s point of view, the test is this: are you publishing the message you are supposed to publish?
From the consumer’s point of view, the test is this: are you consuming, handling, and processing that message correctly?
You do not need every test to spin up the entire world and prove every service talks to every other service through Kafka.
That does not mean you never have broader integration tests. But if every test requires the whole distributed system to be running, then testing is going to be painful regardless of whether you are using HTTP, Kafka, RabbitMQ, Azure Service Bus, or anything else.
Event Driven Architecture Is Not Your Whole Architecture
Event driven architecture is not your architecture. It is part of it.
It is not a full system replacement where you replace all your HTTP calls with asynchronous events. That’s not the case at all.
There is a combination of synchronous communication, asynchronous communication, events, commands, request reply, queries, and more. You need to pick the right style based on the outcome you are trying to accomplish.
It’s not about blindly following a pattern.
If you take a tangled synchronous system and convert everything to events without understanding commands, boundaries, ownership, tracing, failures, and compensation, you probably did not solve the problem. You just made a different version of it.
The issue is not event driven architecture by itself.
The issue is applying it everywhere, treating every message as an event, losing visibility, and not having the tooling or understanding to operate the system.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.