Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
I’ve noticed a trend, and a lot of people are saying the same thing: just use Postgres as a queue. No Kafka, no Redis, no RabbitMQ, just one database for everything.
And I totally get it. I get the appeal. There are fewer moving parts. There is less infrastructure. There is only one thing to run.
But what feels simple at the very beginning can often lead to a lot of complexity later.
It’s like using Excel when you really need a database. Sure, it holds data. You understand Excel well. But are you really about to build a relational engine on top of it?
YouTube
Check out my YouTube channel, where I post all kinds of content on Software Architecture & Design, including this video showing everything in this post.
Postgres as a Queue
So, could you use Postgres as a queue? Sure. That can work. But Postgres, Kafka, Redis, RabbitMQ, guess what? They are not interchangeable. They are not even close to the same thing.
Postgres obviously is a data store. Kafka is a distributed log. Redis is a data structure store. RabbitMQ is a message broker. They all store data, and they all store data differently. But that’s not the issue.

The issue is that they expose different semantics, and those semantics are what drive the trade offs.
So guess what that means? You have to add the semantics yourself. You have to add the behavior and the complexity that comes with it.
If You Want to Use Postgres as a Queue
So we’re talking about using Postgres as a queue. Well, it’s not a queue. It’s a data store. But can we leverage it like a queue? Sure.
But a queue is not the product. A queue is just a set of behaviors and things that you’re going to need to think about if you’re going to leverage it as a queue. And this is where the complexity comes in.

These are the kinds of things you need to start thinking about. What happens when a message is taking too long, or something occurs and it stalls out and never gets processed? Well, that’s your visibility timeout.
How about if there is a failure? Do you want to retry? Do you want to retry immediately? Do you want some kind of backoff so you can retry later if it’s more than just a transient issue?
What about dead lettering? There’s just a failure. There’s something completely wrong and it’s not going to work. You just want to put that message in a dead letter queue. How are you implementing that?
Ordering. Do you need ordering? Ordering is a tough scenario, especially when you’re talking about concurrency and using the competing consumers pattern. And of course, if there is some type of failure later on, maybe it is in your dead letter queue, how are you dealing with replay?
So if you want to use Postgres as a queue, you absolutely can. But guess what? That’s where the complexity lies. You have to add the semantics on top of it. You do not get them for free.
Just because you store a row in a database does not make it a queue. You have to add the behaviors.
The Implementation Tax
So here’s what I’ll call the implementation tax that you’re going to need to pay.
We’ll start with visibility timeout. What happens typically with a broker is when a consumer starts processing a message, there’s going to be some invisibility timeout. Let’s just say it’s 60 seconds.
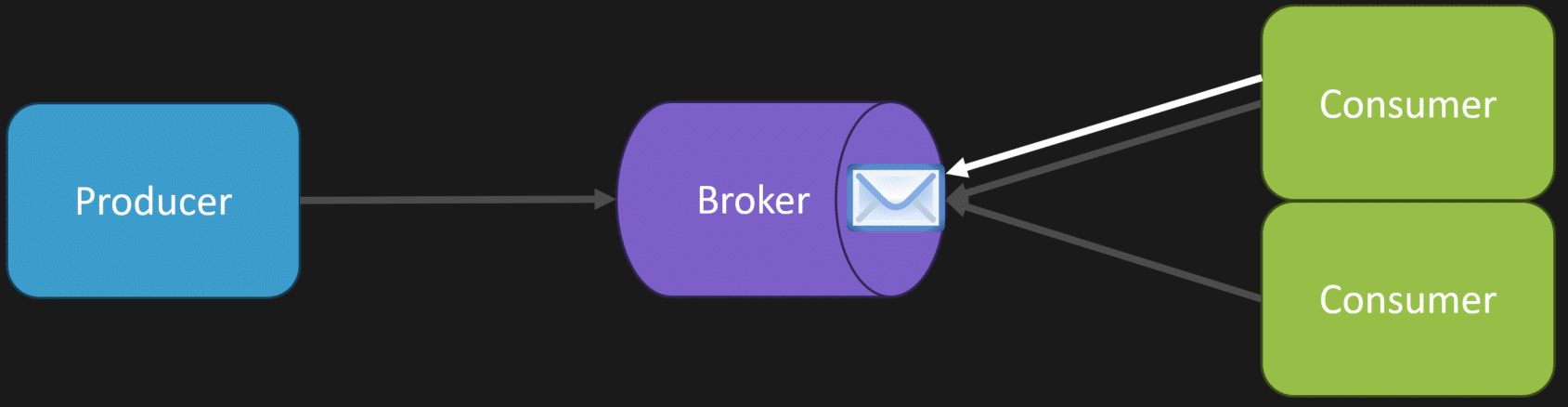
That means the consumer has 60 seconds to acknowledge back to the broker that, yes, it fully processed the message. If it does acknowledge that, then that message is removed from the broker so another consumer doesn’t get it.
However, if it doesn’t, if that consumer does not acknowledge back to the broker in that 60 seconds, then another consumer can pick up that message.
Now for implementation, you might just think, okay, we’ll just put a timestamp on when the message actually got delivered to the consumer and when it may be acknowledged. But is that really going to be that simple? You might have some contention there.
Hang on though. Let’s keep going.
Competing Consumers
The competing consumers pattern is ultimately what allows you to scale out and process more messages concurrently.
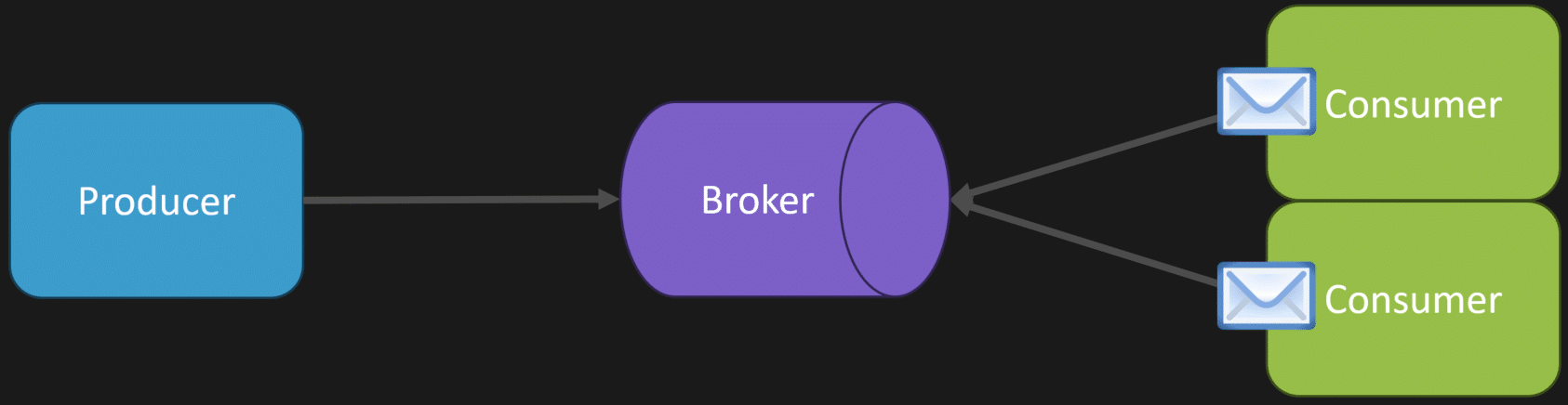
So we have a message come into our broker, or into our actual database. We may have one consumer pick up that message because it has no work to do. Then we might have another consumer, another instance, another thread, whatever the case may be, that’s available. It can pick up another message and process it concurrently at exactly the same time.
This just allows you to scale out.
But how do we implement that?

How we can implement it in Postgres is we start a transaction, then we select from our queue table. Let’s say we’re just doing one row at a time. The magic here is the FOR UPDATE SKIP LOCKED.
Really what we’re doing is we’re locking our records, and then we’re skipping any other rows that are already locked. We process our message, everything’s good, then we can delete it from our queue, then we commit our transaction.
That can work.
The Trade Off With Polling
Now, for the invisibility timeout though, you might have noticed I didn’t do anything, because another solution is just to do it in application code. Have your thread, or whatever it is, be terminated after a particular time, which ultimately kills your connection or your transaction after your 60 seconds.
But the issue here is your consumers need to poll the database.
So you’re really in this trade off that you have to deal with. If I poll too often, is that going to hurt my database in terms of performance? Or if I don’t poll that often, does my throughput and my latency, in terms of how quickly I process messages in that queue, go way down?
So there’s this balancing act that you need to find.
Now, you can use LISTEN/NOTIFY, but that’s really just like saying, “Hey, go check out the table. You got to do something.” And if you’re using competing consumers, then you’re notifying all of them.
The Complexity Doesn’t Go Away
Now, I can keep going on with the complexities of retries, dead letter queues, backoffs, and so on. I gave you the list, and there’s a lot more.
Those are things you’re going to have to deal with.
But there are benefits.
One Big Benefit: No Outbox Pattern
One of the biggest benefits that’s going to be noticeable is that you don’t need to have the outbox pattern.
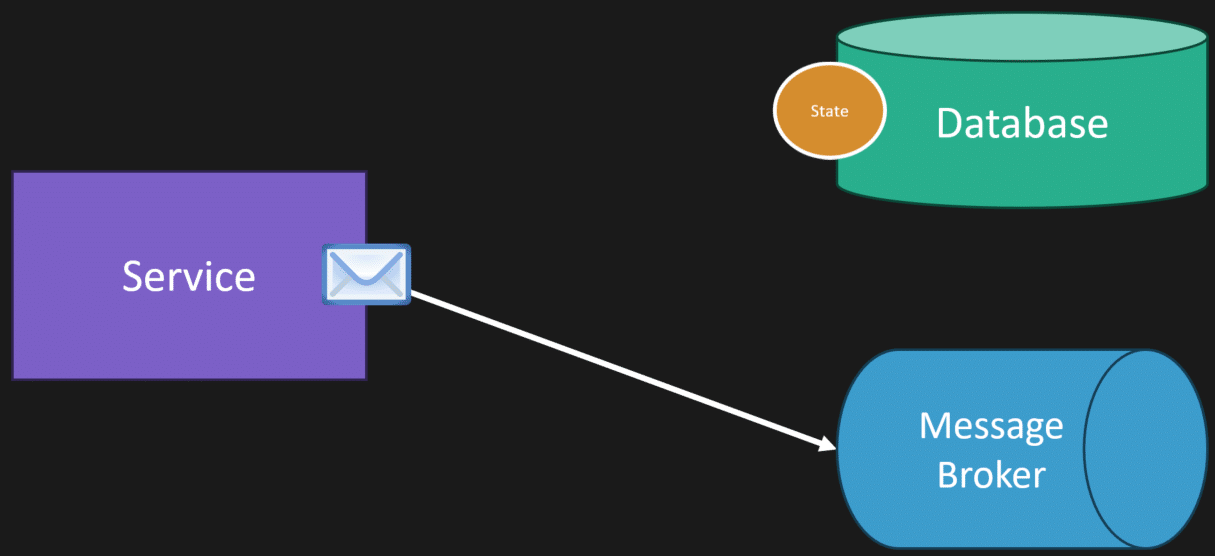
The way the outbox pattern works is because you have a dual write problem. Typically, you have a broker and a database separately, and you want to reliably publish messages along with your state. But you don’t have that problem because your queue is in the same database.
So typically what would happen here is we have our state, we’re saving it to our database, something happened, and then we want to publish a message to our broker, to our queue, for something to get processed asynchronously.
This is the dual write problem.
Guess what? You don’t have this problem, because when you’re persisting your state, you don’t have another connection or some other infrastructure like your message broker or your queue. You’re persisting your state and your message in your queue within the same transaction.
So reliable publishing of messages, you got it out of the box.
The Questions I’d Be Asking
So here are the questions.
If you’re going to use Postgres, or really any database, as a queue alongside your business data, these are the questions I’d be thinking about.
What’s the workload? Can it handle it? Do you know it can handle it?
What kind of retention do you need?
What kind of throughput do you need?
Is polling going to work? Is it not going to work? Can you have some other means?
How well do you understand the database, like Postgres, that you’re using? Can you really leverage those skills?
Do you know all those semantics that you’re going to need to apply on top of it?
Know the Trade Offs
So my answer isn’t, “Well, you should never use Postgres as your queue.” That’s not the case at all.
Really, my answer is: know your trade offs, and know when it’s a viable option and when it’s not.
Postgres, Kafka, Redis, RabbitMQ. Very different tools.
Can you use them as a queue? Sure.
Are you adding a lot of complexity along the way? Possibly, depending on what semantics and what behaviors you need.
One Big Note
There is one big giant note to all this, which is if you’re going to use some type of library, a messaging library specifically built on top of this, that kind of provides all the semantics and all the patterns for you so that you don’t have to go down the road of implementing it yourself, that’s the way to go.
There are some, especially in the .NET space. There are a lot of them that can be used as a transport, as a message transport, for persisting your messages in a database.
So I’m totally with it.
Again, I’m just saying realize the trade offs that you’re making when you’re using a tool that wasn’t specifically designed for being a queue.
Postgres as a Queue
So yes, you can use Postgres as a queue.
The point isn’t that you should never do it. The point is that a queue is more than just storing rows in a table. A queue comes with semantics and behaviors, and if you use Postgres for that job, you’re the one who has to provide them unless you’re using a library that already does.
That’s the trade off.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.