Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
What’s overengineering? Is the outbox pattern, CQRS, and event sourcing overengineering? Some would say yes. The issue is: what’s your definition? Because if you have that wrong, then you’re making the wrong trade offs.
YouTube
Check out my YouTube channel, where I post all kinds of content on Software Architecture & Design, including this video showing everything in this post.
“The outbox pattern is only used in finance applications where consistency is a must. Otherwise, it’s just overengineering.”
Not exactly.
“CQRS is overengineering and rarely used even at very high scale companies. One master DB for writes and a bunch of replica DBs for reads are sufficient.”
No. And it has nothing to do with scaling.
“Event sourcing, another overengineering term, but in reality, most production systems do not implement strict event sourcing as described in books and system design articles. In the practical world, only current state is stored in the primary DB and events and business metrics are stored in an analytics DB.”
The giveaway that this is wrong is the discussion of business metrics related to event sourcing.
In the “practical world”, I’ll give some examples where event sourcing is natural.
Let’s go through them one by one, explain what they are, and when you should be using them.
The Outbox Pattern
Is it about finance? It has nothing to do with finance. Is it about consistency? Yes, that part is correct. It’s really a solution to a dual write problem.
Here’s the dual write problem.
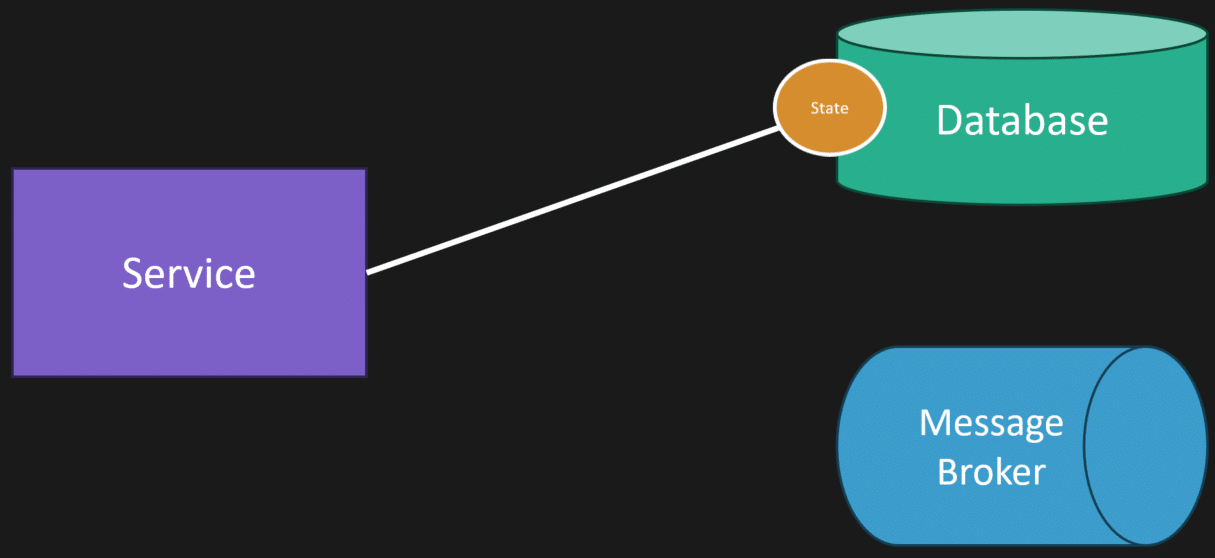
You have your application. Some action gets invoked. You persist a state change in your system.
That’s the first write. The second write is you need to publish an event and write a message to a message broker so other parts of your system know it occurred. That’s the second write.
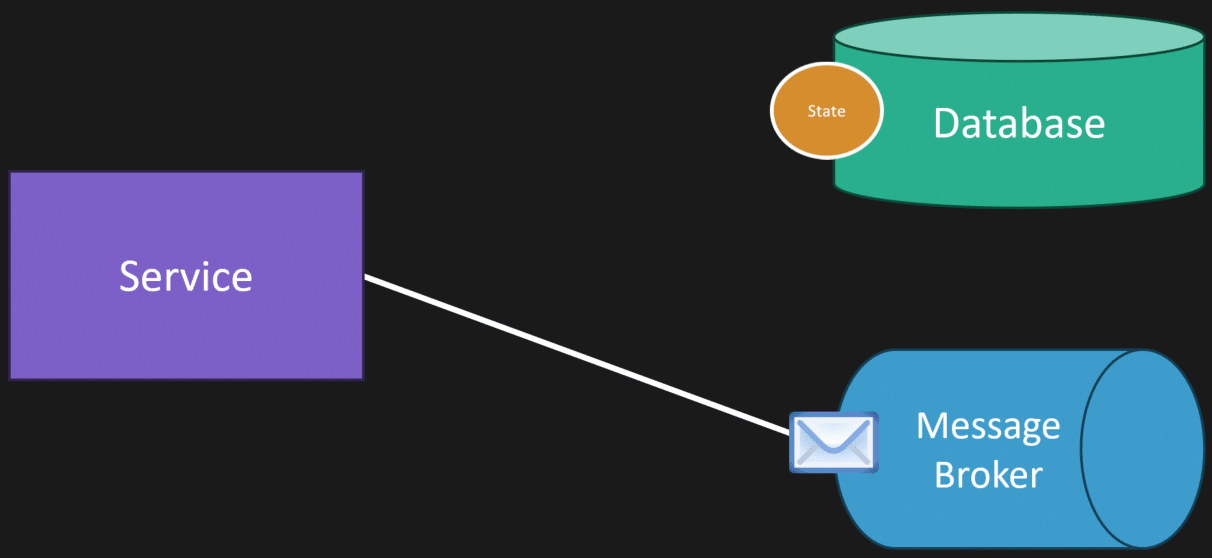
Here’s the issue. It fails in between. So you do the state change. Everything passes. Everything is saved. Transaction is good. But then you fail to publish the message to your message broker. Now you’re inconsistent. Your state change happened, but the event never got published.
Is it a big deal if you fail to publish that event? It depends what you’re using the event for, and what downstream services care about. If it’s best effort metrics or analytics, it might not be a big deal.
If it’s part of a workflow, it can be a much bigger deal. You want that consistency, and that’s where the outbox comes in.
So how do you solve the dual write problem? Like most problems, don’t have it in the first place.
To solve the dual write problem, we’re going to have a single write. That means you persist your state to your database and within the same transaction you persist the message to an outbox table in that same database.
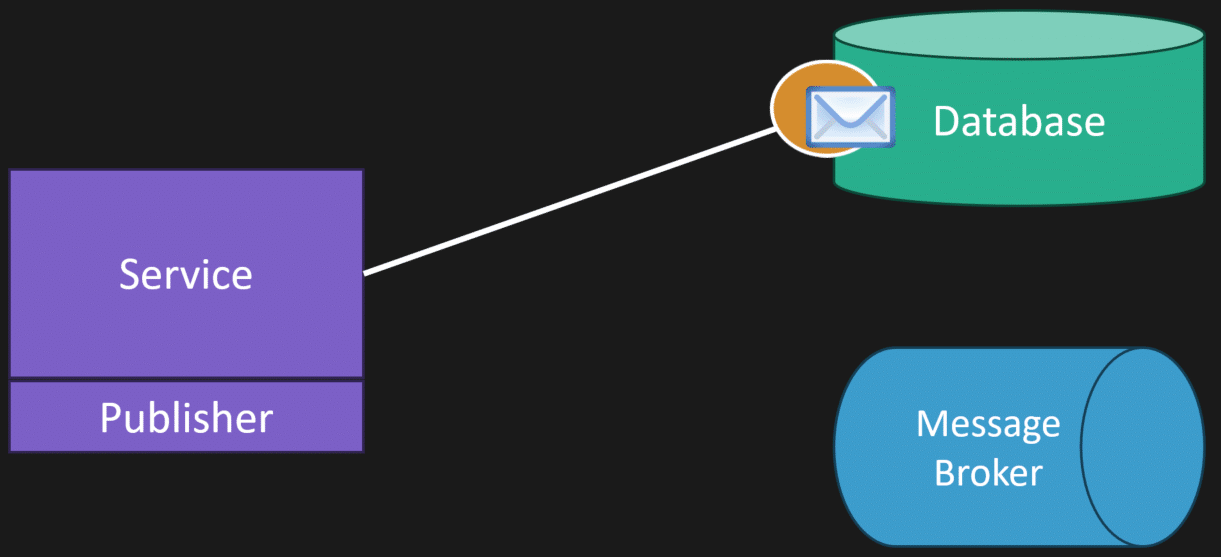
Separately, you have a publisher that queries the outbox table, pulls messages that need to be published, and pushes them to your message broker. If it succeeds, it reaches back to the database and marks the message as completed or deletes it from the outbox table.
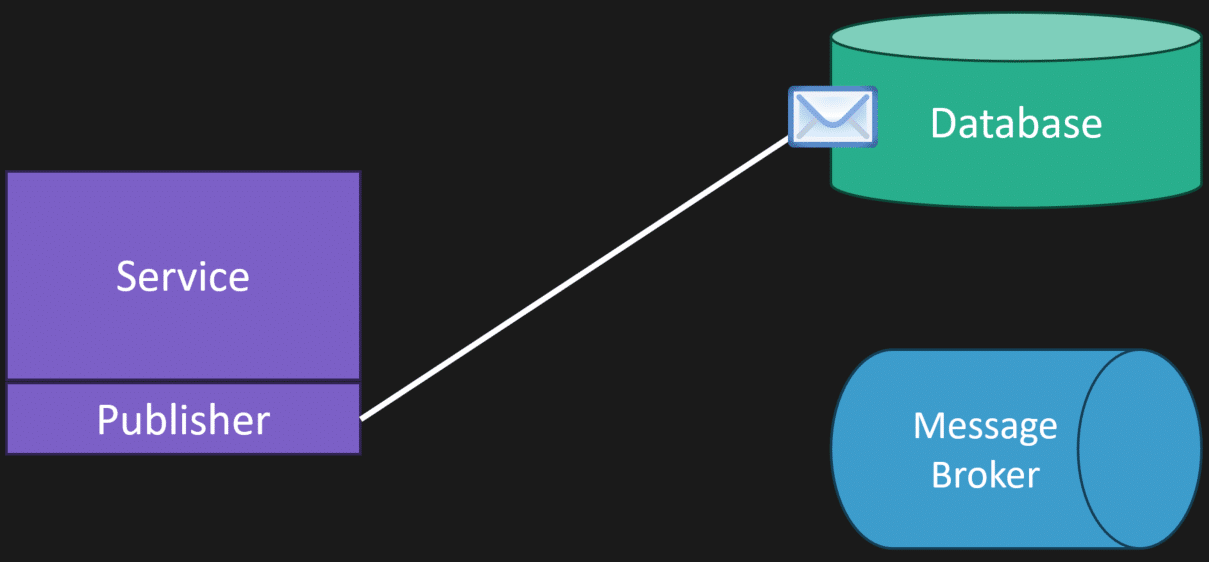
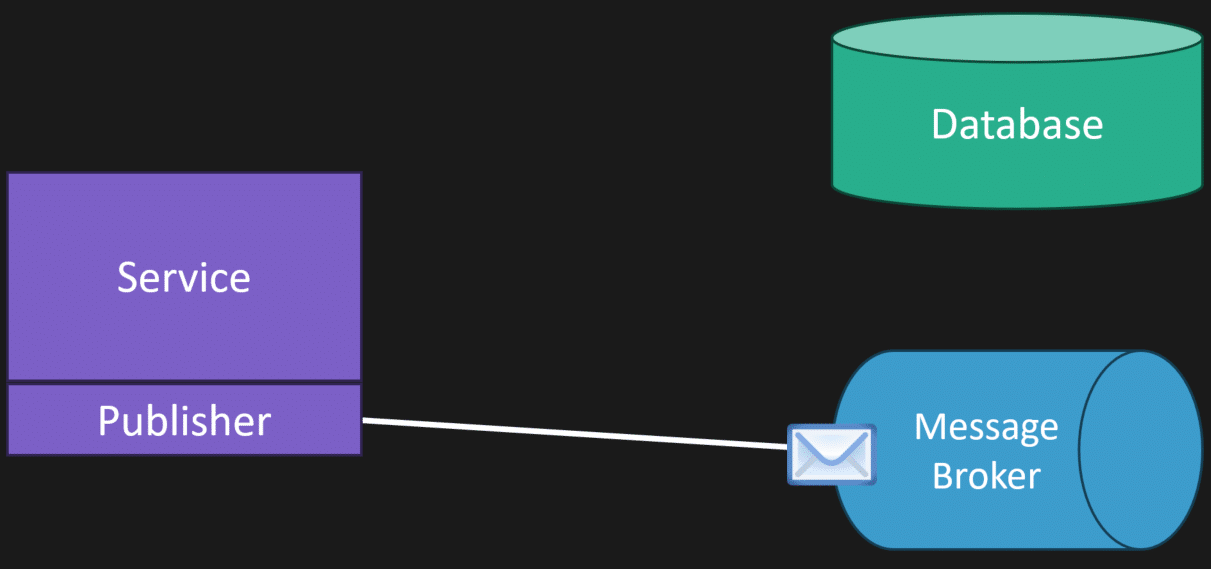
If there’s a failure, you retry. You haven’t lost any messages you wanted to publish.
So is the outbox pattern overengineering? It totally depends on your use case.
If you’re using events as a statement of fact that something occurred within your system and other parts of your system need to know it happened, then it’s probably not overengineering.
If you’re using events as best effort analytics and it’s totally fine if some events aren’t published because nobody depends on them, and lost messages are fine, then yes, it’s overengineering.
One side note: if you’re using a messaging library, it probably already supports the outbox pattern.
CQRS
“CQRS is overengineering and rarely used even at very high scale companies. One master DB for writes and a bunch of replica DBs for reads are sufficient.”
This is confusing two things entirely. It’s talking about scaling at the read write database level, when in reality this is about your application design.
CQRS literally stands for Command Query Responsibility Segregation. Commands change state. Queries read state.
That has nothing to do with databases. One database, two databases, whatever the case may be.
This is about having two different code paths for different responsibilities.
But since scaling was brought up, especially on the query side, that’s the angle I want to tackle. In a lot of query heavy systems, you often have to do a lot of composition.
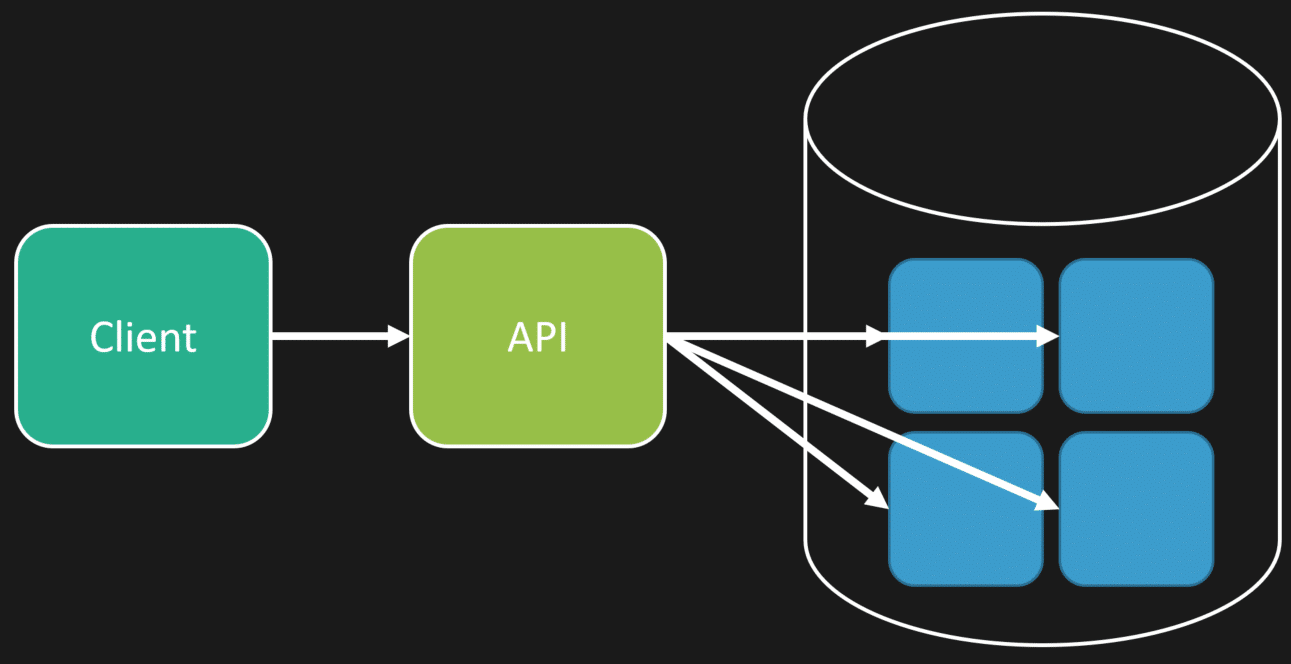
That composition could be to a single database, multiple databases, a cache, whatever. But you’re making multiple calls to different places to compose data together to return to a client.
Because a lot of systems experience this, people create views or materialized views so you’re not doing all of that composition at runtime.
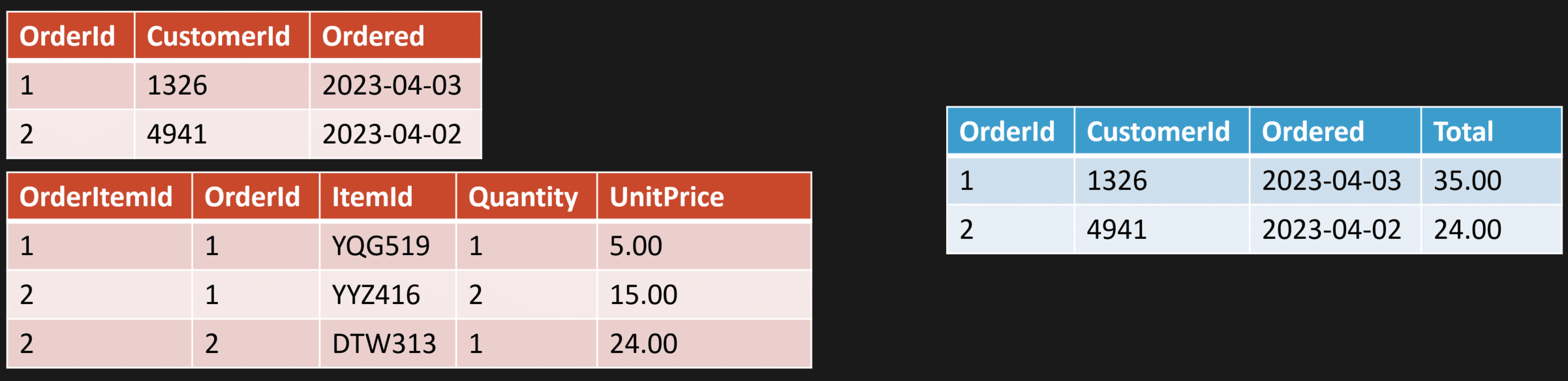
Instead, you have a separate table, a view, a different collection, a different object, something that represents what’s optimized for a specific query.
Example: an order and line items.
Maybe instead of joining tables and calculating totals on every request, you have a view that does it.
Or you have a materialized view that’s persisted and updated every time there’s a state change to an order.
So when you make a state change, your command updates your write side. Maybe that’s a relational database with normalized tables. And because you have a materialized view, you update that too. That could be in the same transaction. Then when a query comes in, you read directly from the materialized view.
This is all about optimizing reads or writes.
In my example, it’s optimizing reads, using a materialized view.
It doesn’t need to be that at all. It could be a relational database, a document store, a single table, a collection, some object that already contains what you need.
The point is you have different code paths, so you have options.
You could still have your query side do composition and your command side use the exact same database, the exact same schema, and update what it needs to update.
You just have the option to do different solutions if you have different code paths.
So is CQRS overengineering? Not really. You’re likely already doing it in some capacity because you already have different paths for reads and writes.
Where this gets conflated is when you start thinking about it purely from a scaling perspective. If you’re doing a lot of composition and you add read replicas, that’s fine.
But here’s the question.
Are your read replicas eventually consistent?
Because that plays a part in the complexity you’re adding by just adding read replicas. If you want pre computation because you want materialized views to optimize the query side, that’s a strategy if you need to optimize.
Event Sourcing
“In the practical world, only current state is stored in the primary DB and events and business metrics are stored in an analytics DB.”
We’re talking about different things here. Events are facts. What event sourcing is doing is taking those facts and making them the point of truth.
Then you take that point of truth, that series of events, and you can derive current state or any shape of data from any point in time.
Let’s use a practical example because there are a lot of domains that naturally have events. You can just see them. A stream of things that occur.
Here’s a shipment.
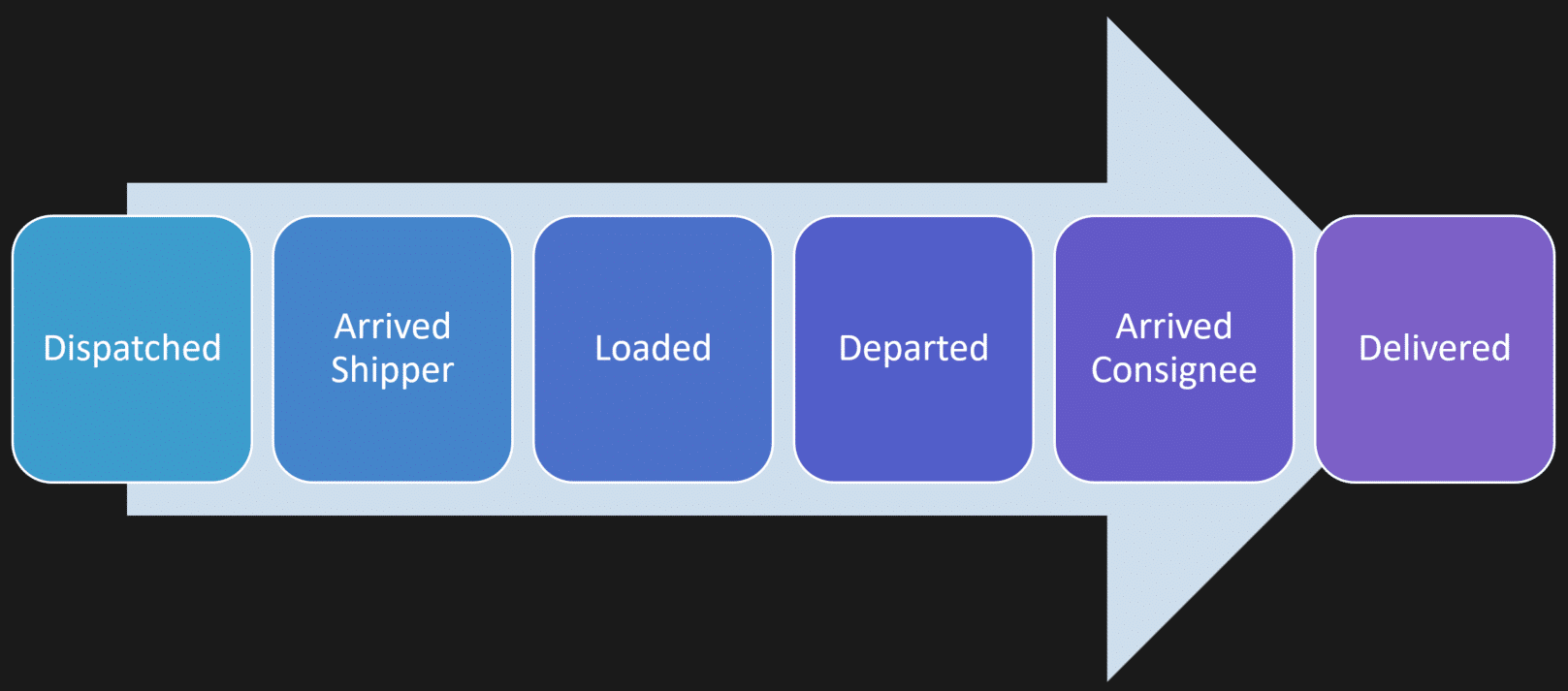
You persist these as a stream of events for the unique thing you’re tracking.
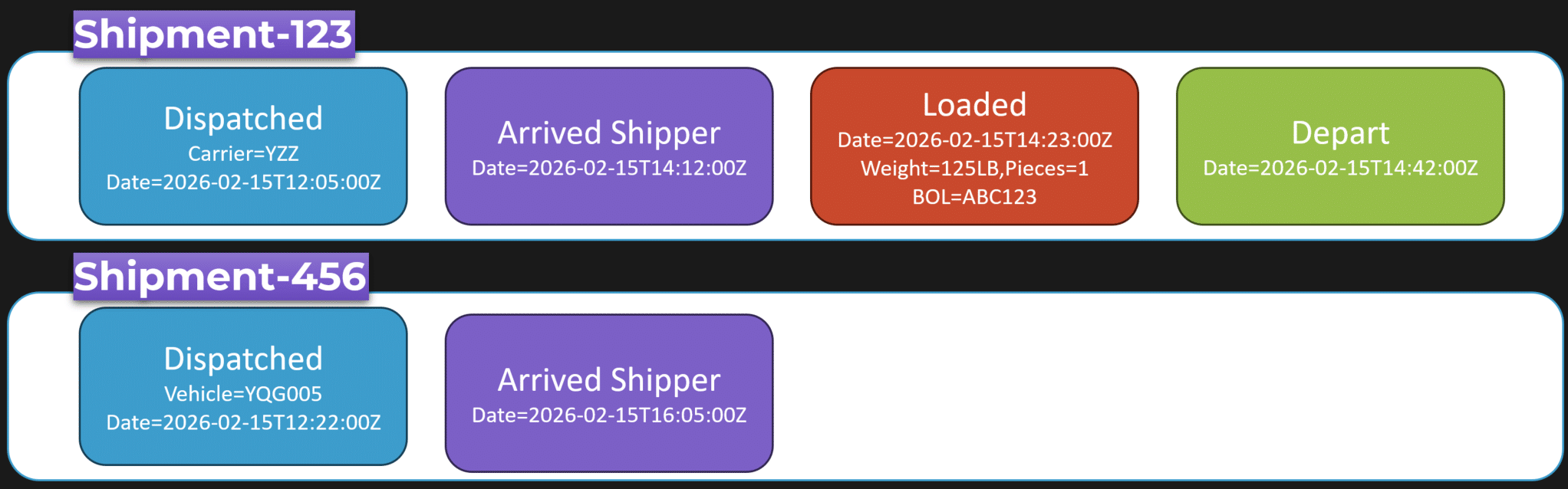
Shipment 123 has its own series of events. Another shipment has a different series of events. Those event streams are the point of truth.
You can derive current state from them.
It has nothing to do with analytics, but you can use them for analytics because just like current state, you can turn them into any shape you want.
So if you have an event stream, you can transform it any way you want.
Maybe you transform it into a relational table so analysts can write SQL like “select all shipments dispatched on a particular day”. Or maybe you transform it into a document shape that’s optimized for an application query.
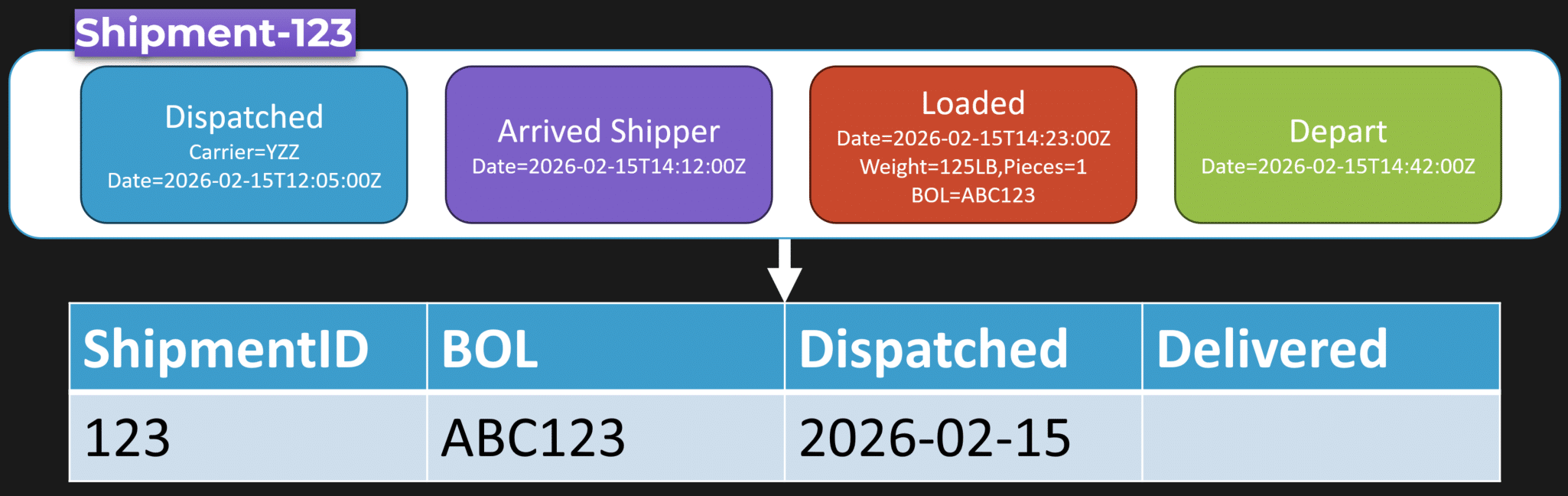
That’s the point.
Your source of truth becomes an append only log of business facts, events. Your state is derived from those events.
A lot of the issues I read about people having with event sourcing are twofold. First, they’re not actually doing event sourcing. They have an event log, but it isn’t the point of truth. Their real database is still current state, and the event log is just “extra”. Or they’re using events as a communication mechanism with other services like a broker, which is a different thing.
Second, there’s a huge difference between facts and CRUD. “Shipment created” is not an event. That’s CRUD. “Order dispatched” is an event. Something happened.
“Shipment modified” is not an event. “Shipment loaded”, “shipment arrived”, “shipment delivered”, those are events.
Is event sourcing overengineering? It can be if all you view your system as is CRUD, and that’s how you build systems.
But there are a lot of domains where, once you start seeing it, you naturally see a series of events and it becomes obvious that’s where event sourcing fits.
The Real Point About Overengineering
Everything has trade-offs.
If you do not understand a concept, you won’t be able to understand what those trade-offs are, because you don’t even know what they are.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.