Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
DHH had a take on microservices in small teams that is getting a lot of attention. And while I agree with what he’s pointing out, all of these types of conversations miss what actually matters. This is not about microservices or a monolith or small teams.

Now what’s implied here is microservices is much more difficult to understand the full context. I agree, given how most people think of microservices. You can think, well, I got all these services and yeah, I don’t know how anything happens end to end, and what service interacts with what service. Yes, that’s a problem.
It’s a problem, but not the root cause.
YouTube
Check out my YouTube channel, where I post all kinds of content on Software Architecture & Design, including this video showing everything in this post.
The Root Problem Is Coupling
The root of the problem is coupling.
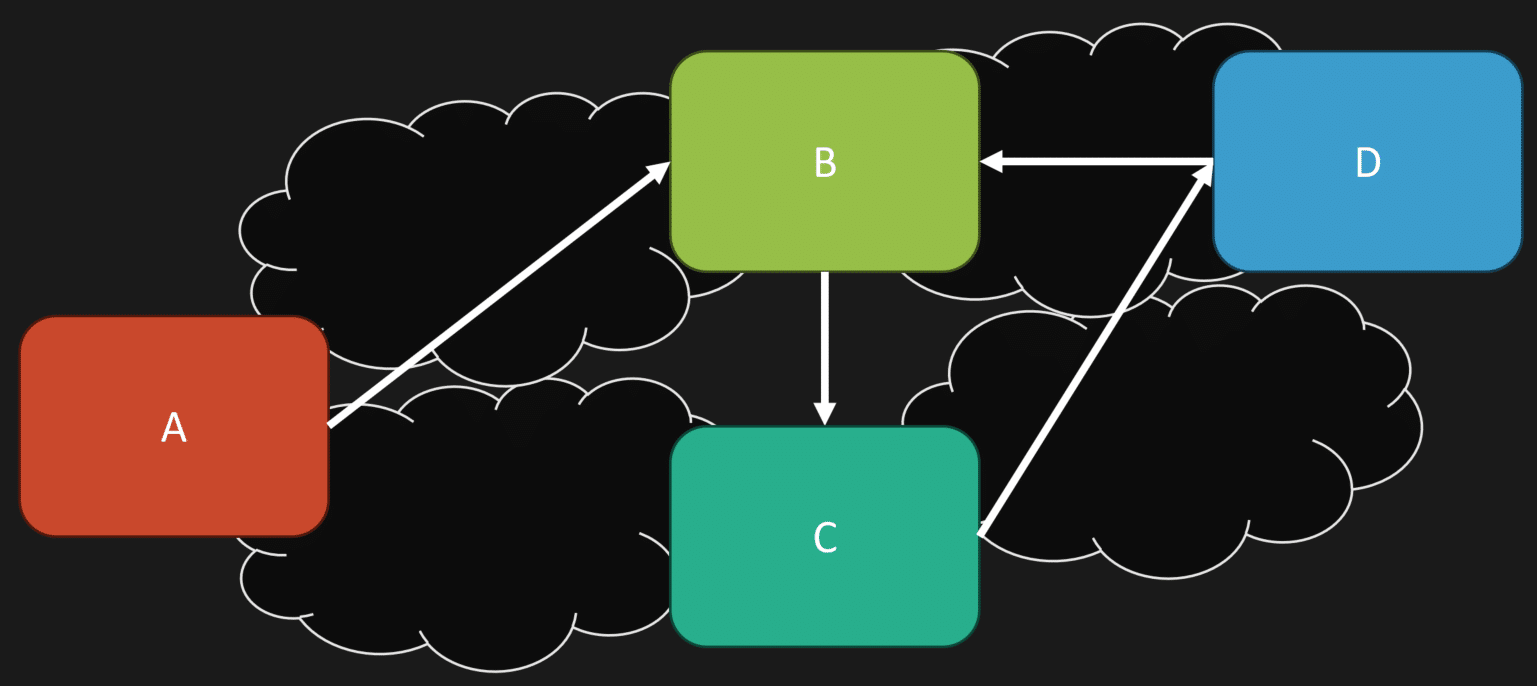
So if you have a high degree of coupling, let’s say we’re talking about a monolith here, yes, you’d be able to kind of navigate this a little bit better. Try to understand how each different part of your system is interacting with a different part. And yes, it’ll be much more difficult if all of a sudden these are all microservices and now you’ve introduced a network boundary.
Microservices is a physical architecture choice. That’s what you’re choosing when you introduce it. You’re introducing network boundaries.
But regardless if you have a monolith or microservices, whether you’re a small team or not, the key is to define logical boundaries.
Logical Boundaries vs Physical Boundaries
There’s a difference between logical boundaries and physical boundaries.
Half the issue here is that microservices define and force you to be a one to one.
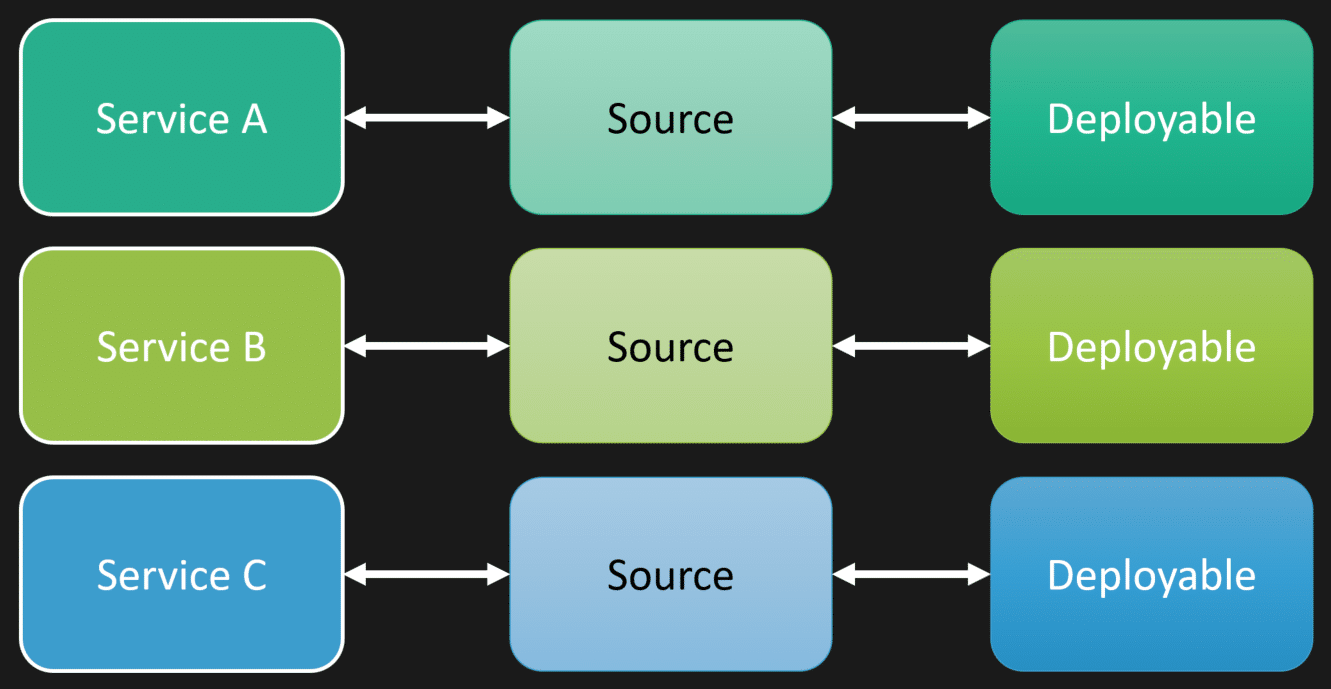
Meaning, what we defined as a logical boundary of service A, B, and C, they likely end up with their own source repository. Even if it’s a monorepo, you have your own source that’s specific for that logical boundary, which guess what, gets built and turned into some type of deployable, whether it be some executable, a container, whatever, some unit of deployment.
We’ve turned everything into a one to one to one.
That can be different when you often think about a monolith, or what people would classify as a modular monolith. You have all these different logical boundaries within your monolith, within the same source codebase, that gets turned into a single deployable unit.
You can build a monolith with strong logical boundaries. You could be doing the same with microservices.
On the flip side, you can build an absolute turd pile of a monolith because you have weak boundaries, or none at all. Same goes with microservices.
What We Are Really Arguing About
What we’re really arguing about here with microservices is whether the cost of introducing a network boundary is worth it.
And he points out that cost.
“Then comes the operational farce. Each service demands its own pipeline, secrets, alerts, metrics, dashboards, permissions, backups, and rituals of appeasement.”
I don’t think that list is exaggerated at all. It’s a lot of complexity and has a high cost.
So the question is, do you get enough value from being able to deploy independently for the cost. This is about a trade off.
He continues with,
“One bug now requires a multi service autopsy. A feature release becomes a coordinated exercise across artificial borders you invented for no reason.”
Hang on there.
You just have a high degree of coupling. Artificial borders, absolutely you want borders. Should they be artificial. No. They should be cohesive around the capabilities of your system.
If you have a high degree of coupling, that’s your problem. That’s not just some random thing. It wasn’t invented. You created this. You created the coupling.
Whether you have microservices, is it going to be much more difficult to debug and troubleshoot because of that network boundary. Absolutely. I’m not disputing that.
But the root cause here is because of all the coupling, which directly relates to the comment, “You don’t deploy anymore. You synchronize a fleet.” No, that’s because of coupling.
More specifically, what people feel the pain of is temporal coupling.
If you were in your monolith and you had the same type of degree of coupling, you might not feel as much pain, but that coupling is still there and the pain is still there. It’s just hidden.
When you introduce that network boundary, it just exposed it. Because now you have all the distributed nature of HTTP, gRPC, whatever, however you’re distributing over the network. Retries, latency, it’s just exposing it all of a sudden. But the mess was already there.
“You Are Forced to Define APIs Before You Understand Your Own Business”
Here’s what I think is one of the most important parts of this post.
“You are forced to define APIs before you understand your own business.”
If you’re starting to build a system and you don’t really understand yet what the domain is, what the business is, I always say defining logical boundaries or services are one of the most important things to do, but one of the most difficult things to do.
You really need to understand the domain and how the interactions are going to work, because you do not want a high degree of coupling. You want your logical boundaries to be as autonomous as you possibly can be.
They’re often little workflows, a part of bigger workflows. There shouldn’t be a mess of coupling between boundaries.
Typically that happens because you’re more focused on the technical aspect than you are about the actual business behaviors and capabilities of your system.
So while I agree that jumping into microservices and defining network boundaries immediately, that’s going to be much more difficult because it’s harder to refactor. I think everybody can agree on that.
So yes, being in a monolith first, when you don’t understand and you’re trying to mold what the logical boundaries are, yes, it’s going to be easier because it’s easier to refactor.
Which gets to what I like to call the loosely coupled monolith.
The Loosely Coupled Monolith
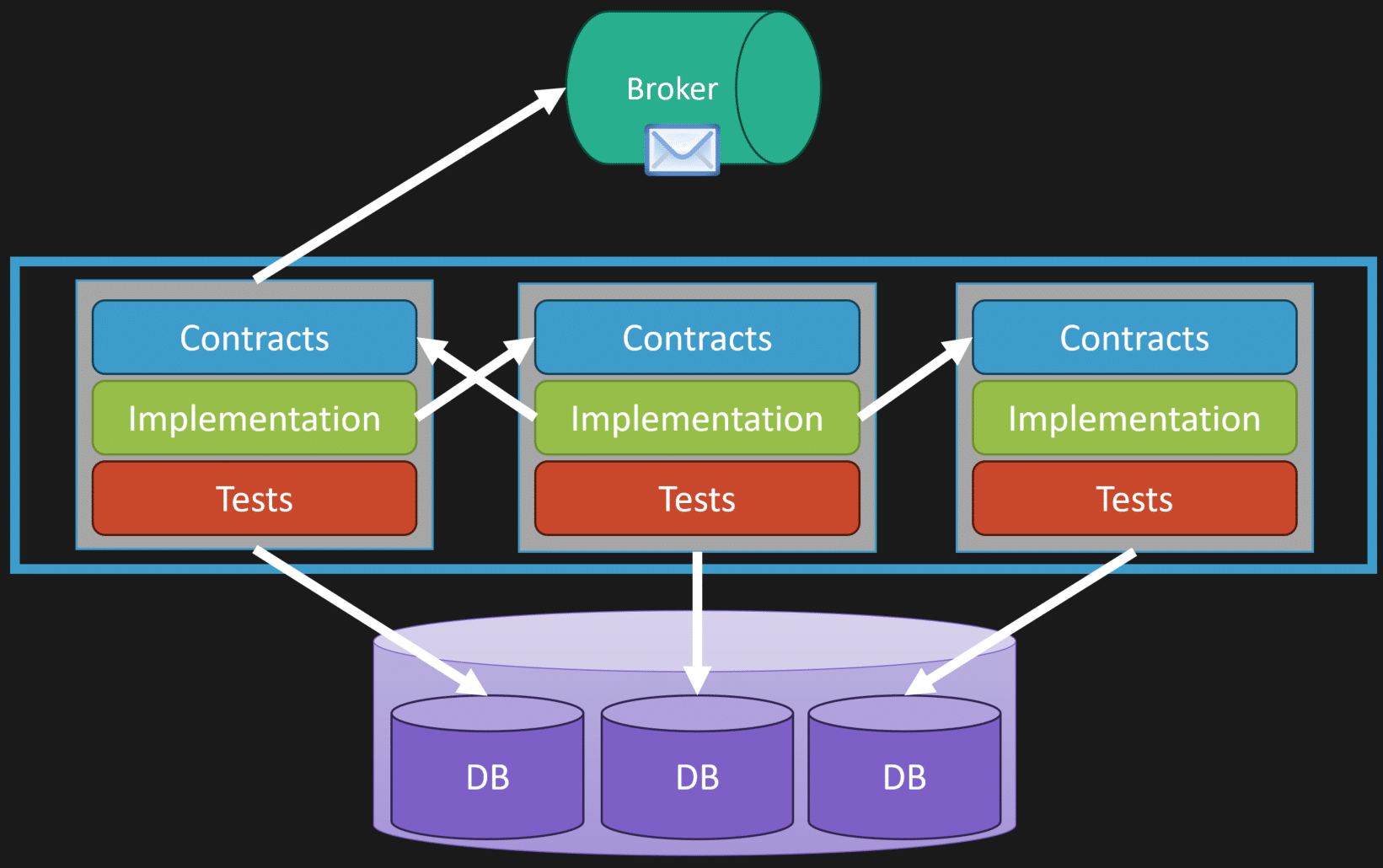
If we think about three different logical boundaries that have contracts, things like messages or potentially interfaces, implementation tests, we can see with my database here, maybe I have one database instance, but within that I have schemas that are specifically owned by a logical boundary.
It’s not a free for all of any logical boundary accessing data from another.
More specifically, what happens then is all your interactions, because of workflows, are done asynchronously via messaging, if you can.
That way we can see, if I’m in a monolith, I have all three deployed together. There’s absolutely nothing stopping you from carving one of them off and making it individually deployable because maybe it has a different cadence of what you want to release. The others can be separate.
You start it off as a monolith. You discover what your boundaries are. And because you might have the need and enough value to make it independently deployable, you can.
So, as long as again, the trade off and the cost is worth it. But that’s specifically because you need something independently deployable, possibly scalable.
“Monoliths Don’t Scale” Is Not Real
“The claim that monoliths don’t scale is one of the dumbest lies in modern engineering folklore.”
I agree.
And the simplest example of this is with the web queue worker pattern.
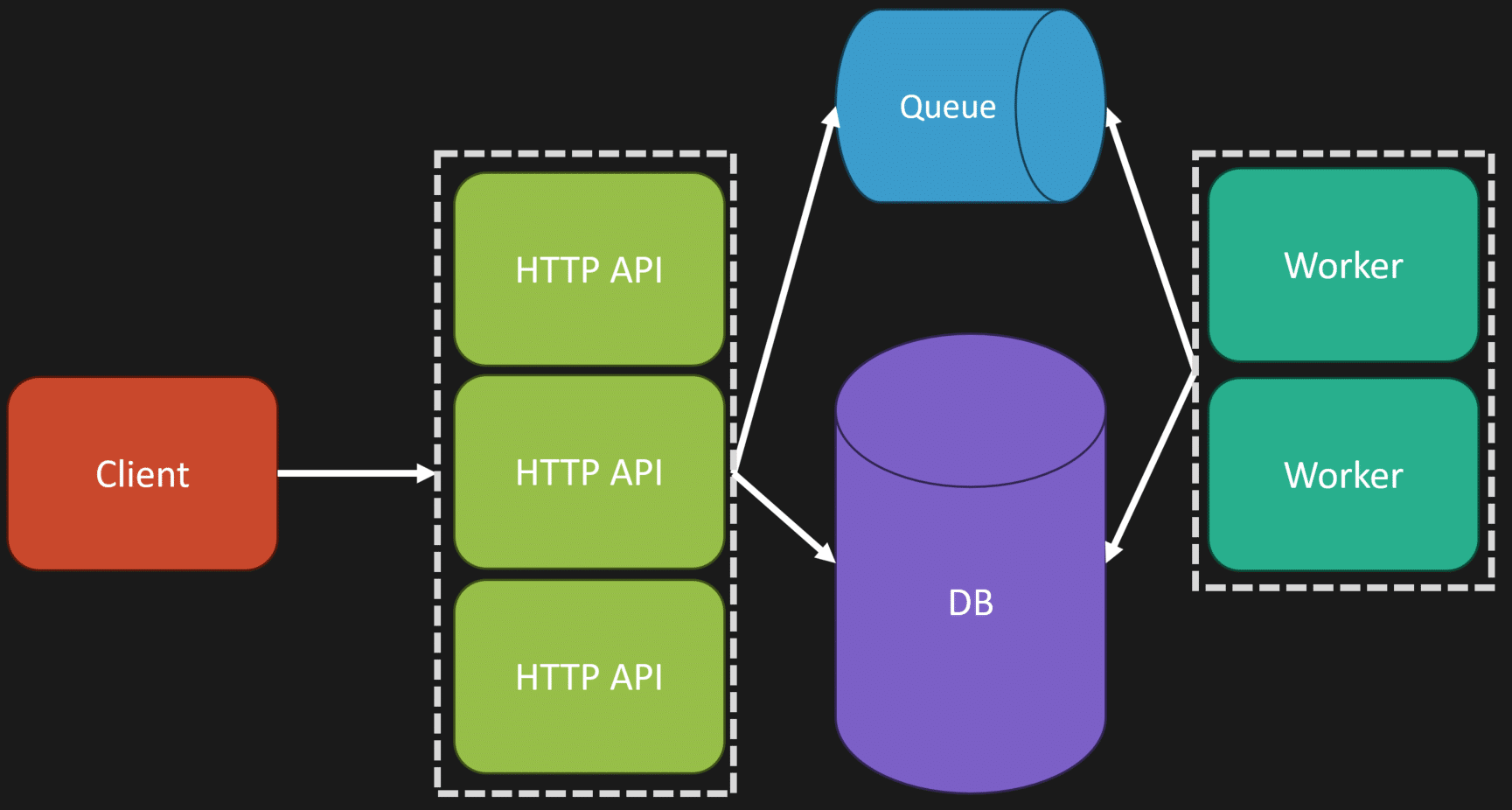
Going back to when I said logical isn’t physical, you can have more than one entry point, or one executable, or one deployable unit, even in your monolith.
In my example here, I have one that’s our HTTP API, could be sitting behind a load balancer, and we’re scaling that out.
But I also have the exact same codebase, but instead its entry point is actually listening to a queue, a message broker, an event log, and performing work asynchronously.
Now, on our database side, you could scale that up. You could scale that out depending on what type of database you’re using, or introducing read replicas.
But there’s so many different ways that you can scale a monolith.
Jumping to independent deployability isn’t necessarily the first thing you need to do for scale.
Stop Making This About Microservices vs Monoliths
Now, while I agree with a lot of what he wrote, I think it’s kind of silly that we’re still even talking about this this way.
This isn’t “microservices good” or “microservices bad” in a small team or whatever context. How about we start talking about the actual underlying issues here.
Adding physical boundaries has a cost. That’s what he was describing. Is the cost worth it? Well, you need to understand what the actual trade-offs are and what the value is.
I think we need to get totally beyond this, because fundamentally, at the root of almost all of this is poor design and poor coupling.
Even if you decided, I’m going to go all in on microservices, and let’s say you lived in an existing system and you knew what those logical boundaries should be, if you designed it correctly, you would not experience the pain of “I have to navigate all these different services to understand this end to end flow and I don’t get this context.”
You wouldn’t have that problem because your services are contained to actually what they do. They’re a part of a workflow. Are they part of a larger workflow. Yes. Would you have all this temporal coupling everywhere like a spaghetti hot distributed mess? No, you wouldn’t.
We’re talking about what people are implementing and how they’re doing it poorly as being like, let’s not do this because people are doing it poorly.
That’s not the case.
Manage coupling and understand when that network boundary is worth it.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.