Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
One of the most common questions I get is how to compose data when different services each own their own data. You might have product details owned by the catalog service, pricing owned by sales, reviews owned by a reviews service, shipping information somewhere else, and order counts somewhere else. How do you get all that data together so you can render a UI or generate a report?
YouTube
Check out my YouTube channel, where I post all kinds of content on Software Architecture & Design, including this video showing everything in this post.
The Problem: Where do you do the composition?

Developers want things to be simple. When a request comes in, they’d like to reach into their own local database and have all the data available within their service boundary. No cross-service calls at runtime, no network latency, no failure modes.
But in a distributed system, you can’t just assume a single source has everything. The data is everywhere, so by default you end up making multiple calls: catalog for the name and description, sales for pricing, reviews for ratings, shipping for delivery windows, inventory for quantity on hand. That runtime composition adds complexity and latency.
Option 1: Compose at Runtime (call other services)
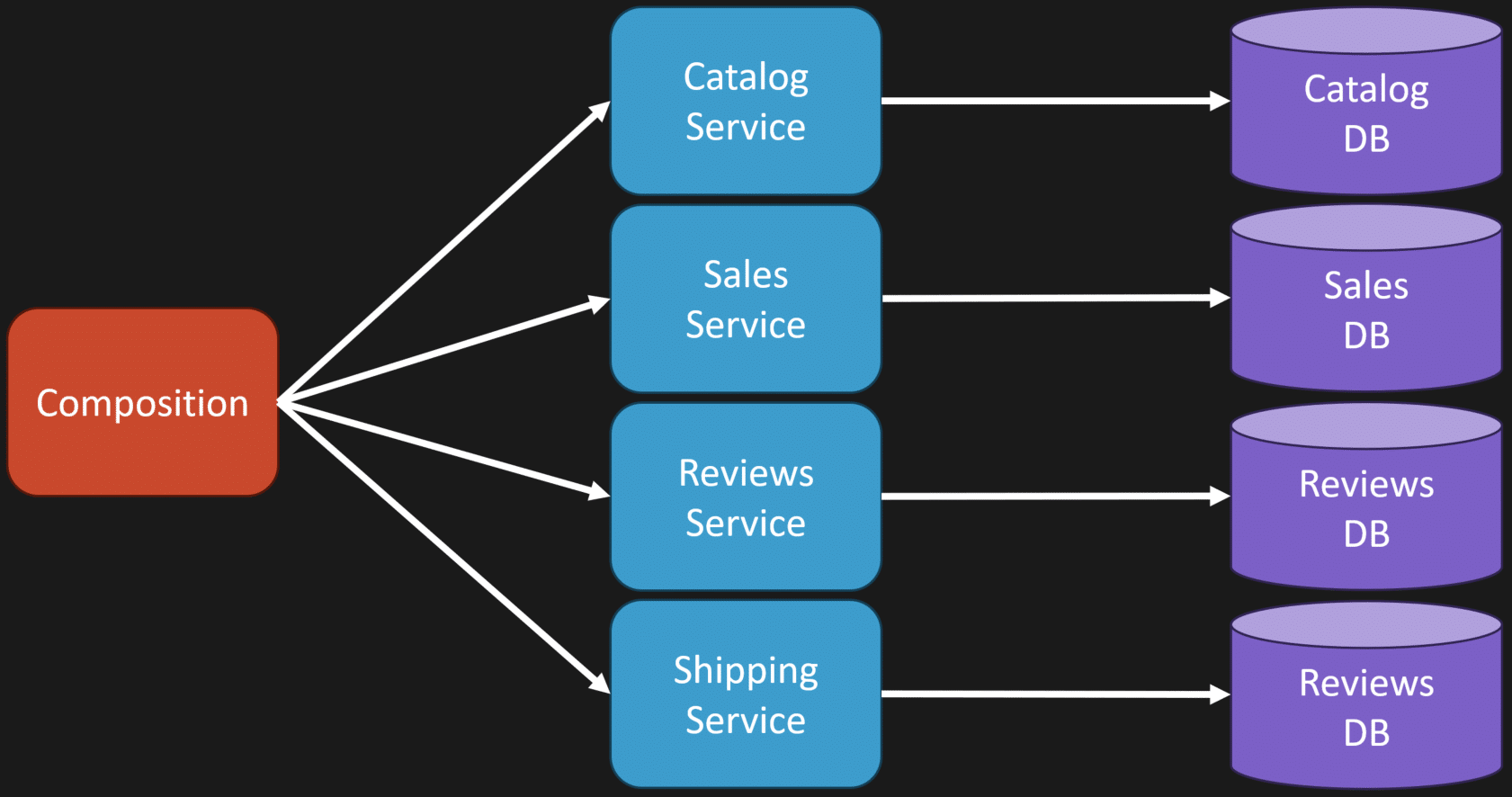
The straightforward option is to do exactly that composition at request time. Your service or an intermediate layer calls each owning service and aggregates the responses. That keeps the data fresh, because you query the source of truth at the moment you need it, but it comes with trade-offs: increased latency, more failure modes, and tighter coupling across services during a request.
Option 2: Pre-compute and Cache (event-driven read models)
Another approach is to pre-compute the shape of the data you need ahead of time so you don’t have to assemble it at runtime. One common pattern is to use events to notify interested services that something changed, and have those services update their own read models into the shape they need to answer requests quickly.
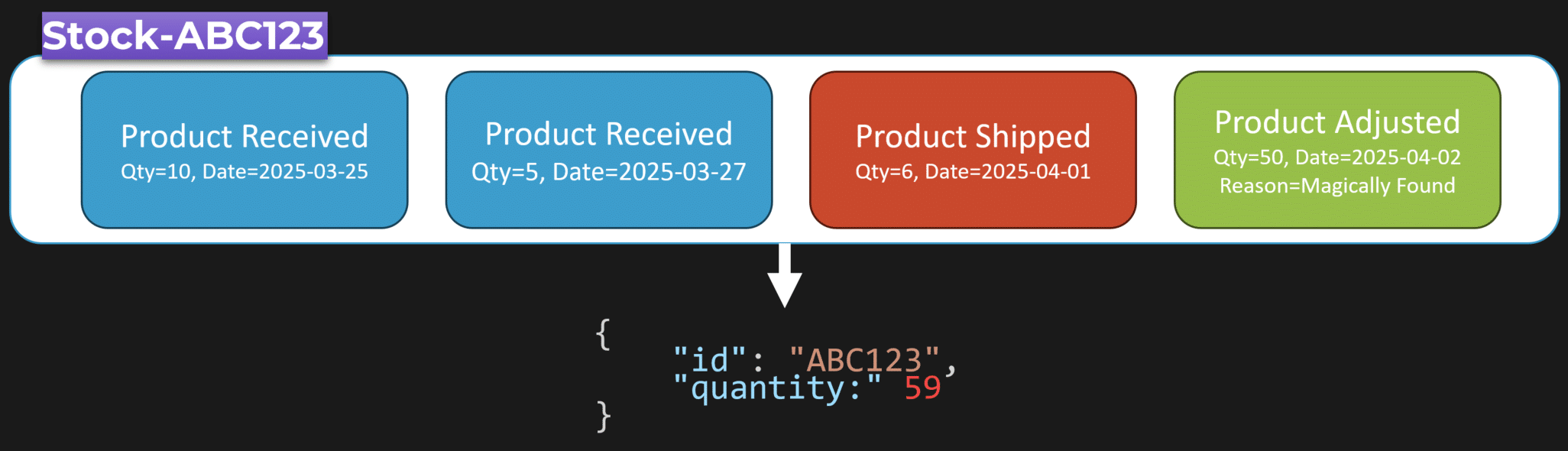
To illustrate, imagine inventory events for a particular SKU. We receive 10 items, then receive 5 more, then ship 6, then an inventory count reveals a box of 50. If you process those events as they occur, you can maintain a current state like “quantity on hand = 59” without recomputing from the raw events at request time. You don’t need to replay the event stream every time a UI needs the quantity; the read model already reflects the current value.
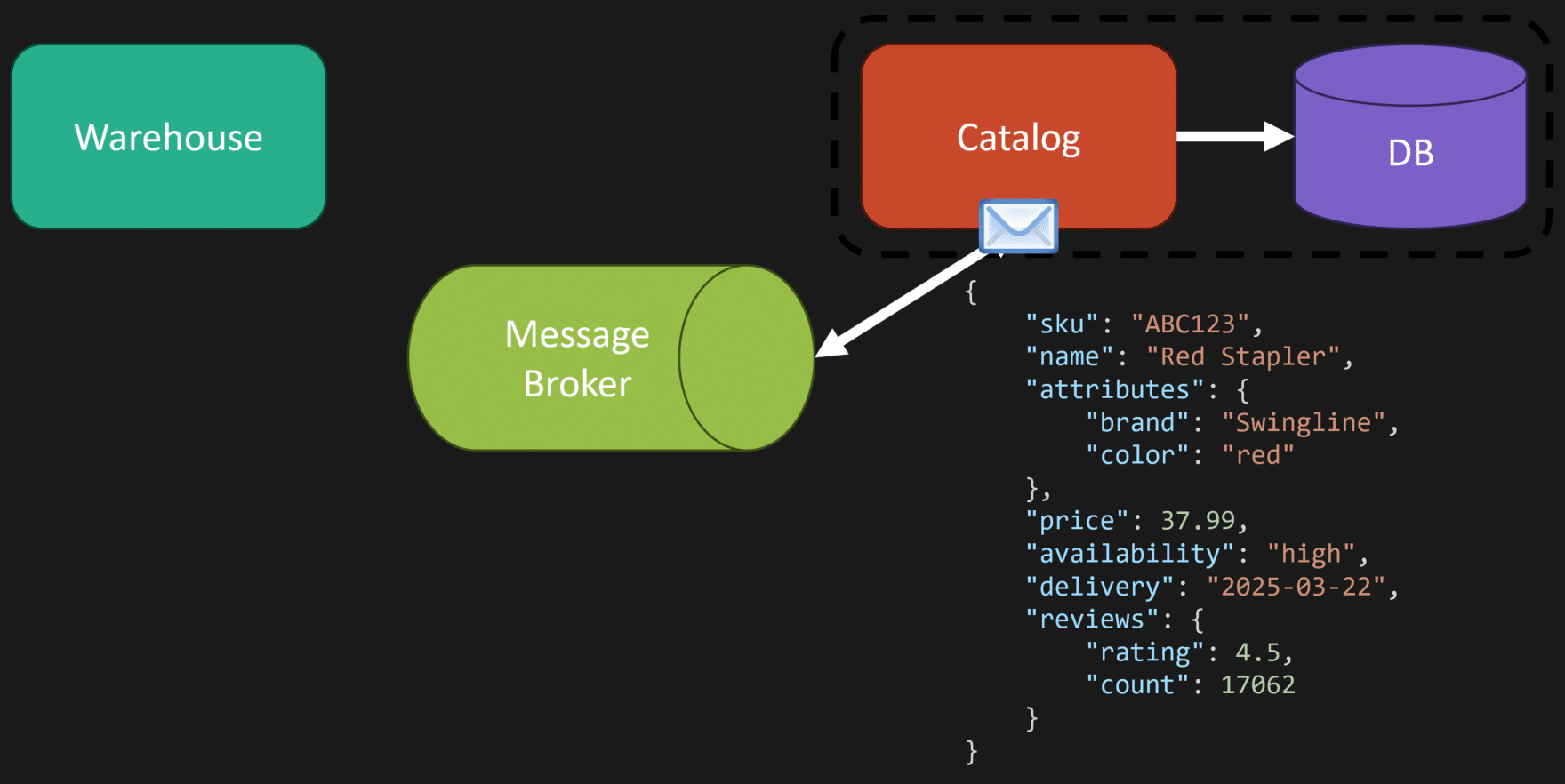
When an event like “product received” is published to a message broker, other services can consume it and update their local data. The catalog service might be listening to warehouse events and change a document field like availability from “out of stock” to “in stock.” That lets the UI display a meaningful delivery promise without calling the warehouse service at request time. Essentially you’re changing the shape of the data ahead of time so the composition becomes simple: query your local database and return the pre-assembled document.
You’re changing the shape of the data. You’re not doing all this at runtime—you’re pre-computing so that when a request comes in you already have what you need.
Trade-offs: Staleness, Incorrectness, and Reconciliation
This pre-computation model gets you back to the simple mode developers want, but it comes with costs. The most obvious trade-off is stale data. By keeping a local cached copy of another service’s data, that copy may lag behind the source.
Worse than stale is incorrect. If an event never publishes or a consumer fails to process an event, the read model can be wrong. Handling that requires extra complexity: periodic reconciliation or checkpoints where you query the source service directly to ensure your cached copy matches the source. You can use events as a change set to keep things up to date and still periodically reconcile from the authoritative source.
It’s not binary. You don’t have to choose pre-computation for everything or runtime composition for everything. Consider the nature of the data. Pre-computation works well when data is not highly volatile or when you’re dealing with a finalized state at the end of a lifecycle—think reporting or data that is unlikely to change after a certain point. For highly transactional or very volatile data, runtime composition may be more appropriate depending on volume and latency requirements.
Practical Guidance
In my experience, a hybrid approach is often the best path. Use pre-computed read models for data that benefits from fast access and is relatively stable. Use runtime composition for volatile, strongly consistent data where freshness matters more than latency. Plan for reconciliation when you cache other services’ data and be explicit about the consistency and staleness guarantees you provide to clients.
Remember that regardless of approach, coupling remains: you still need to know how to assemble the pieces. The decisions are about where that composition happens and what trade-offs you’re willing to accept around latency, complexity, and correctness.
Composing data from disparate services is one of the most common questions I get. There’s no silver bullet—runtime composition gives freshness at the cost of latency and more failure surface, and pre-computation gives speed at the cost of potential staleness and extra complexity for reconciliation. Choose the approach that fits the volatility and lifecycle of your data, and don’t be afraid to mix patterns where it makes sense.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.