Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
I want to talk about something that might sound like a contradiction in terms: the serverless monolith. If you’re scratching your head right now, thinking, “Wait, that makes no sense, serverless is for microservices!” then stick with me. I’m going to clear up one of the biggest misconceptions out there and explain why a serverless monolith is actually a valid strategy for building applications.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
What Is a Monolith Anyway?
When most people think about a monolith for a web app or an HTTP API, they imagine something pretty straightforward. You have your client making an HTTP request. That request might hit a load balancer or an API Gateway, but let’s say it’s a load balancer. That load balancer then directs the request to an instance of your app.
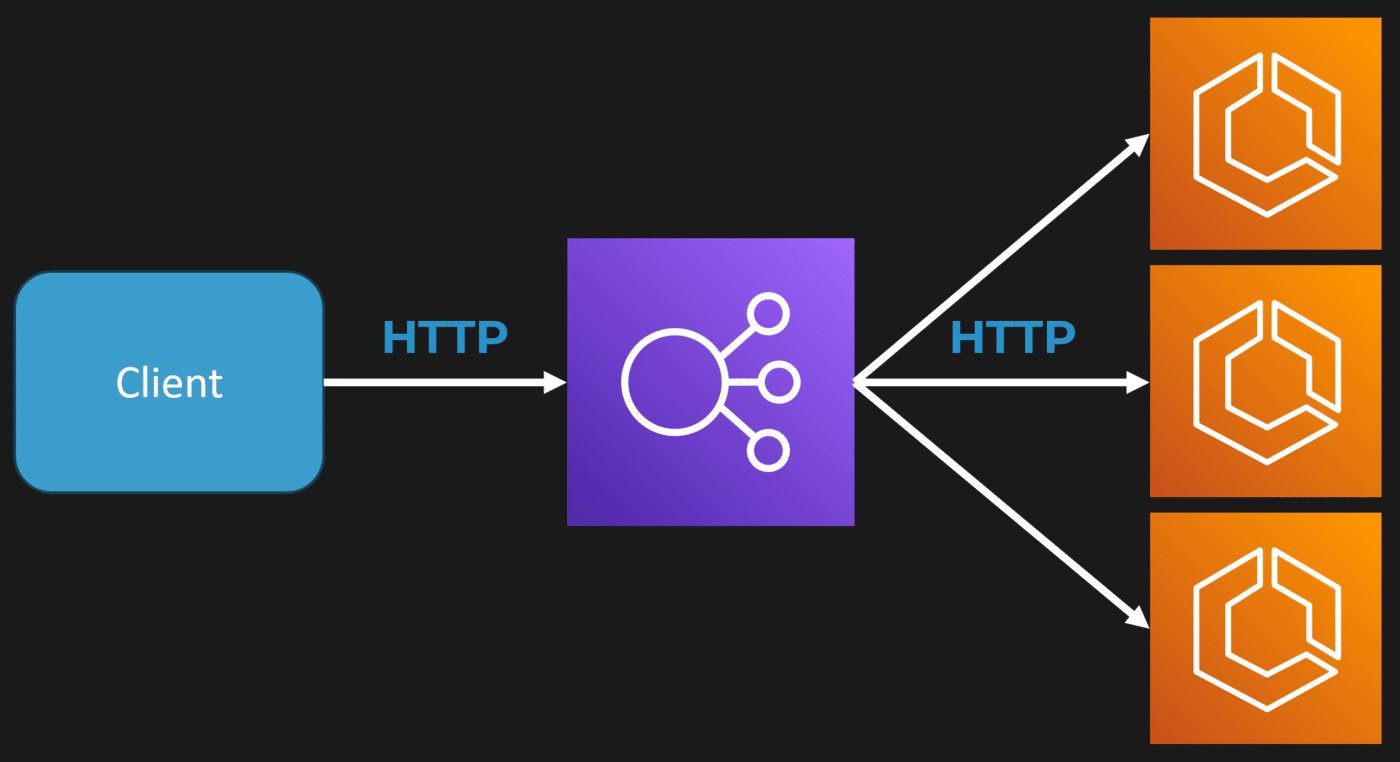
If you’re working in AWS, that instance could be an EC2 virtual machine or a container managed by ECS. Either way, you have one instance of your monolithic web app or HTTP API serving that request. Because you’re behind a load balancer, you can scale out by running multiple instances—whether those are EC2 instances or containers—all handling incoming requests.
The Common Serverless Mental Model
On the flip side, when people hear “serverless,” they often think of the exact opposite of a monolith. They’re picturing microservices or tiny, independent deployable functions that each do one very specific thing. Instead of a large executable, they imagine a collection of small functions, each triggered by specific events.
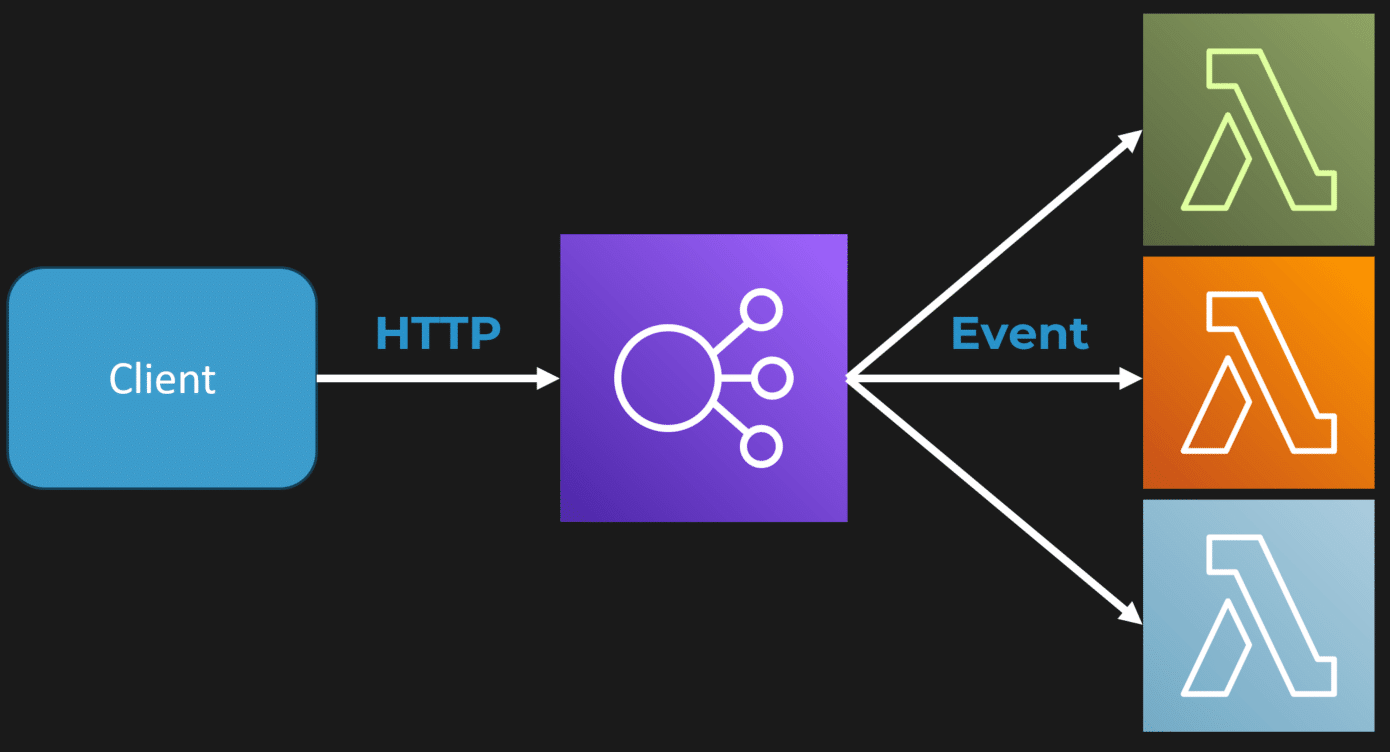
What this looks like in practice is your client makes an HTTP request, which hits your load balancer or API Gateway. That gateway converts the HTTP request into an event and invokes a serverless function—like an AWS Lambda or Azure Function. Each route or API endpoint might trigger a different function, depending on the rules you set up in your API Gateway.
But here’s the kicker: the common assumption that these functions all need to be separate code bases or deployed independently? That’s not true. They can all come from the same monolithic code base and be deployed as a single Lambda function or Azure Function. This is where a lot of confusion starts.
The One-to-One-to-One Misconception
One of the biggest misconceptions I see in the industry is this idea of a “one-to-one-to-one” relationship in serverless architectures. What I mean by that is the belief that each logical boundary or piece of functionality in your code must correspond exactly to one function in deployment. In other words, one piece of functionality in source code equals one deployed unit.
That’s not how it has to be.
It’s perfectly valid to have a monolithic codebase that contains many pieces of functionality but is deployed as a single serverless function. The deployment model—the way your code runs in the cloud—is not the same thing as your architecture. Execution and deployment are different from architectural style.
Understanding the Web-Queue-Worker Pattern
To make this a little clearer, let me explain the web-queue-worker pattern. You have a client making an HTTP request to your HTTP API. This API interacts with your database, then places a message on a queue or publishes an event to a topic in an event-driven architecture.
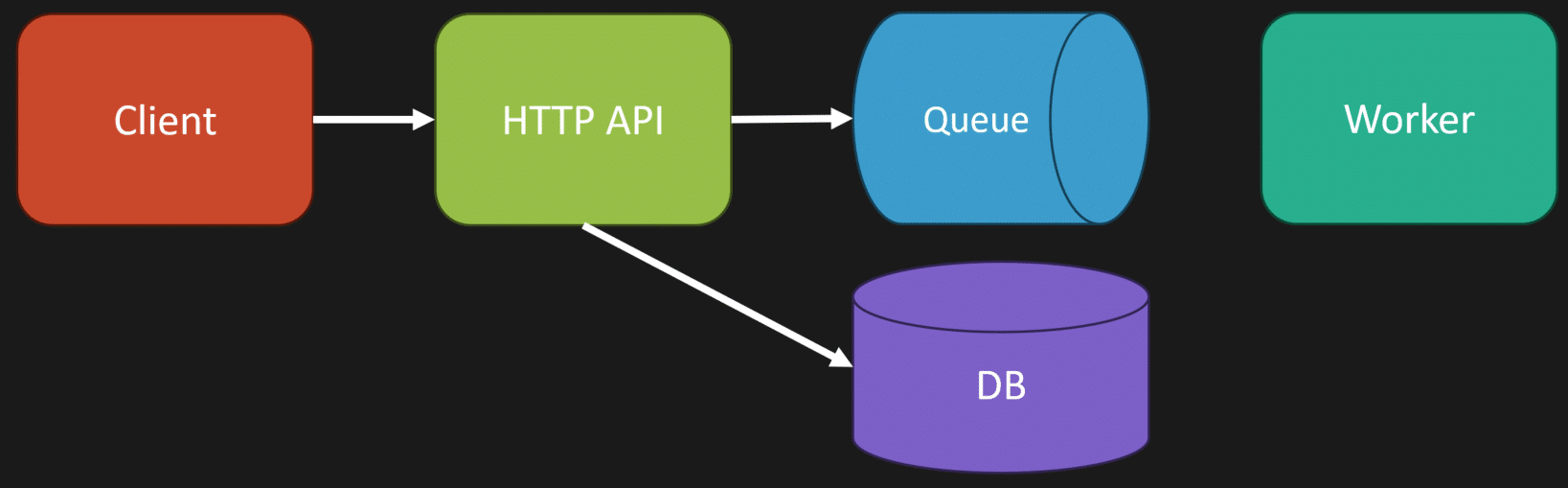
Separately, you have a worker. This worker might be another process, or maybe a thread within your main process. Its job is to pick up messages from the queue and perform work asynchronously—like interacting with the database, sending emails, or whatever else your application needs.
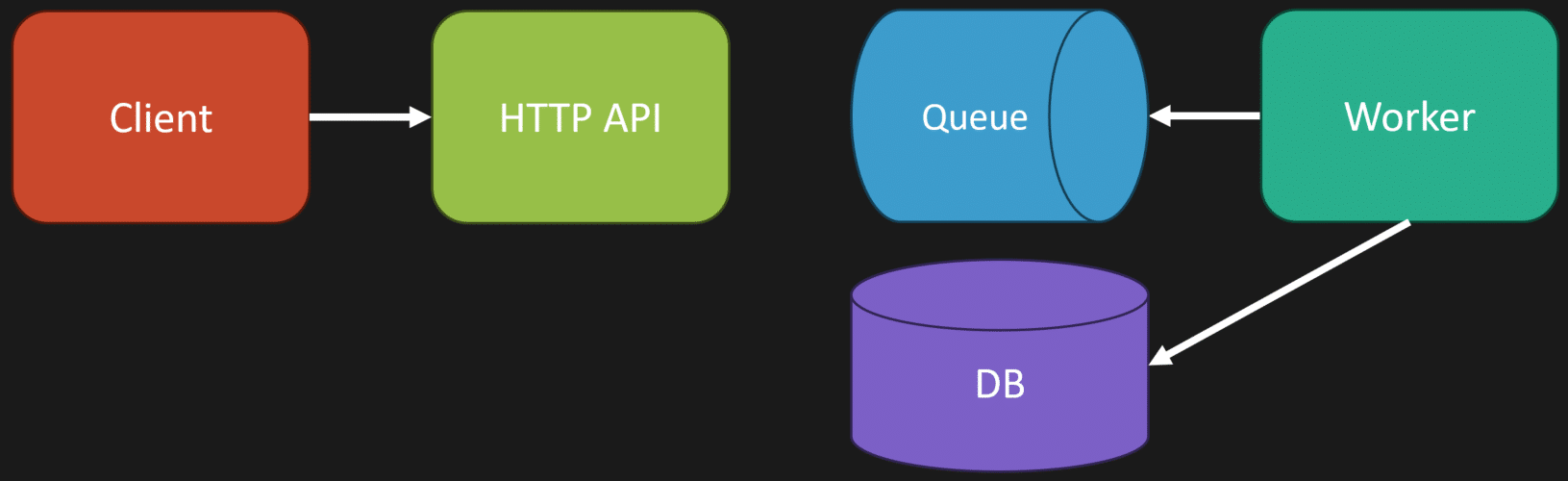
The important part here is that the HTTP API and the worker can be part of the same monolith. They can be the same codebase, built from the exact same source. The difference between them is just the entry point: one entry point handles HTTP requests, while another processes queue messages.
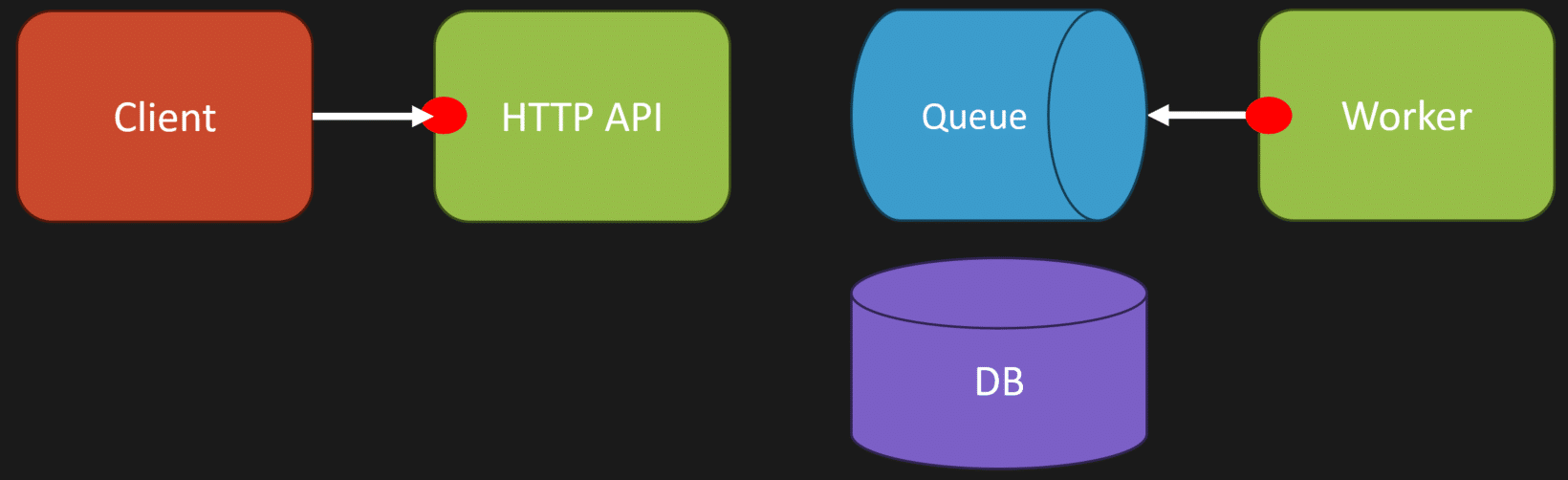
They might be deployed as separate processes or even run on different containers, but it’s still a monolith because it’s the same codebase. How you deploy it doesn’t decide whether it’s a monolith or not.
Debunking the Myth: Coupling Does Not Define a Monolith
Now, a lot of people think of monoliths negatively because they associate them with tight coupling—a big tangled mess of code. They imagine a “turkey pile,” or a “big turd pile,” to be blunt. But coupling alone doesn’t define a monolith.
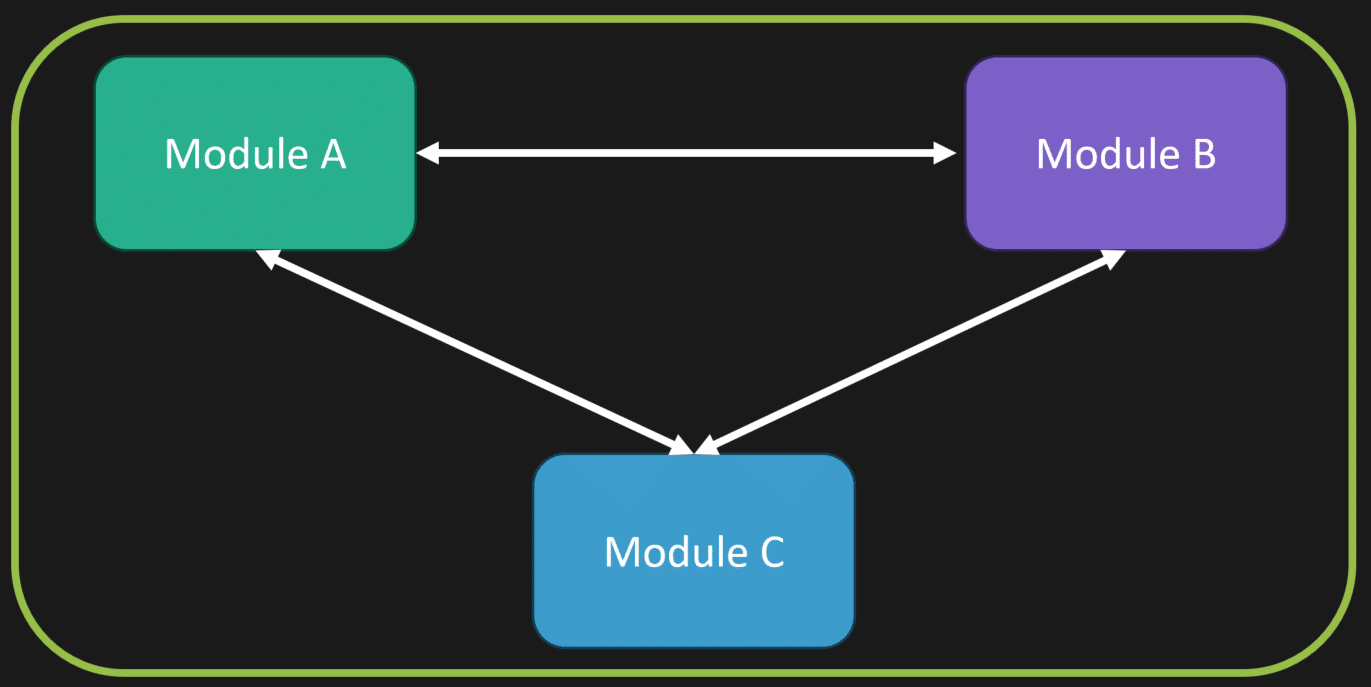
You can have tight coupling in microservices just like you can have tight coupling in a monolith. Conversely, you can have loosely coupled monoliths and loosely coupled microservices. It’s about how you design your communication, how you manage dependencies, and how you organize your code.
For example, if you distribute your application into multiple services but they’re still tightly coupled—maybe they depend on each other synchronously over the network, or one service is written in a different language than another—you might actually have an even harder time managing the system.
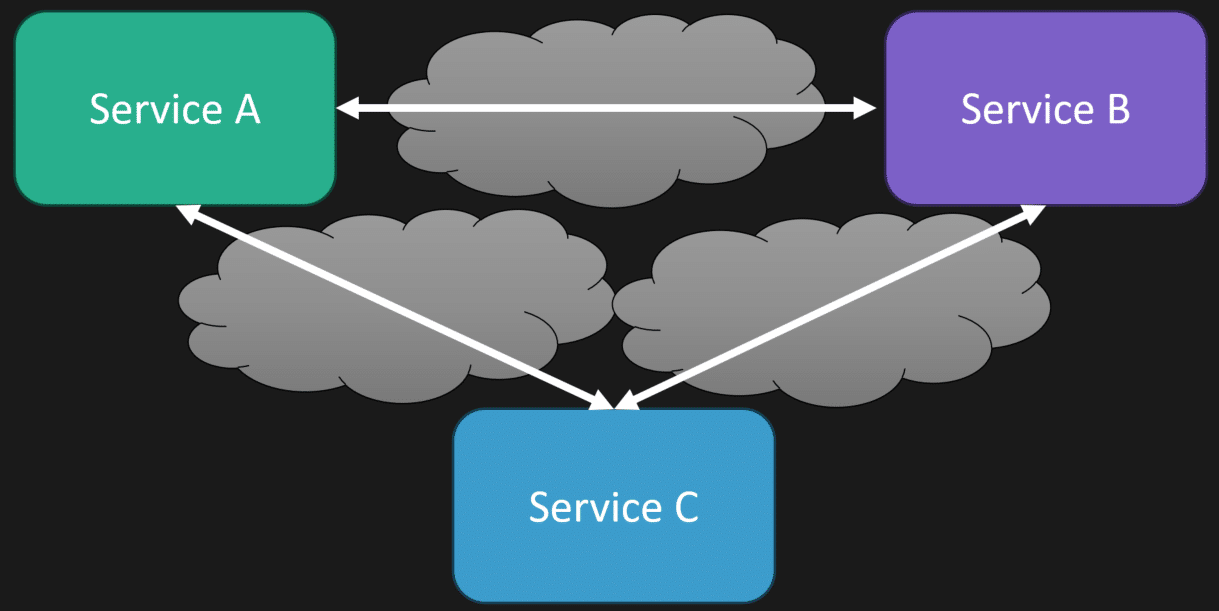
Network hops introduce latency and complexity. Different languages mean different tooling, deployment processes, and operational challenges. So the notion that microservices are automatically better because they’re distributed and monoliths are automatically bad because they’re tightly coupled is simply not true.
Serverless Monoliths Are Totally Doable
So what about serverless monoliths? Are they an oxymoron? Nope. You can absolutely build a loosely coupled monolith and deploy it as a single Lambda function behind an API Gateway.
Your HTTP request comes in, the API Gateway converts it to an event, and invokes a fat function—the monolith. You don’t have to split your code into dozens of tiny functions mapped one-to-one to routes. Instead, you can have a single entry point that routes requests internally inside your monolith.
There’s a lot of tooling that supports this approach. For example, I use the AWS Lambda template with ASP.NET Core minimal APIs. This setup has a separate ASP.NET Core server that translates API Gateway requests into ASP.NET Core requests and then back to HTTP responses. It’s really just one line of code that does all the magic for you.
And it’s not limited to minimal APIs. You can use MVC controllers or whatever you prefer inside your Lambda function. The key is that the Lambda function is just your execution environment, not your architectural boundary.
Serverless is About Execution, Not Architecture
Serverless really defines your execution model and your deployment model—the physical aspects of how your system runs and scales. It doesn’t define your architecture. Whether you’re using microservices, a monolith, event-driven design, or something else entirely, is determined by your architectural styles and patterns, not by whether you’re serverless or not.
When Does Serverless Make Sense?
Now, should you use serverless? That depends on your needs. A lot of the conversation around serverless focuses on scaling up—handling big spikes in traffic and load. But that’s not the whole story.
Here’s a typical scenario: your system has a 9-to-5 load pattern, with lots of traffic during business hours and very little outside of those times. People often think, “What if I get a sudden spike? I want to handle that.” Sure, that’s one part of it.
But what’s more important to me, and where serverless really shines, is scaling down—scaling down to zero. If you have sporadic load or recurring workloads with gaps in between where nothing needs to happen, serverless lets you pay only for what you use. You don’t have resources running all the time that you’re paying for but not using.
That’s the power of serverless: you only pay for execution, not for idle resources. Check out my post Serverless Sucks? for more.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.