Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Here are my 5 most common mistakes in software design that make your code a nightmare to work with. All of these mistakes make your code unmaintainable over time as it grows.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
1. Invalid State and Data Consistency Issues
The first mistake is related to data ending up in an invalid state and having consistency issues. This usually happens because you don’t have good control over what’s changing state.
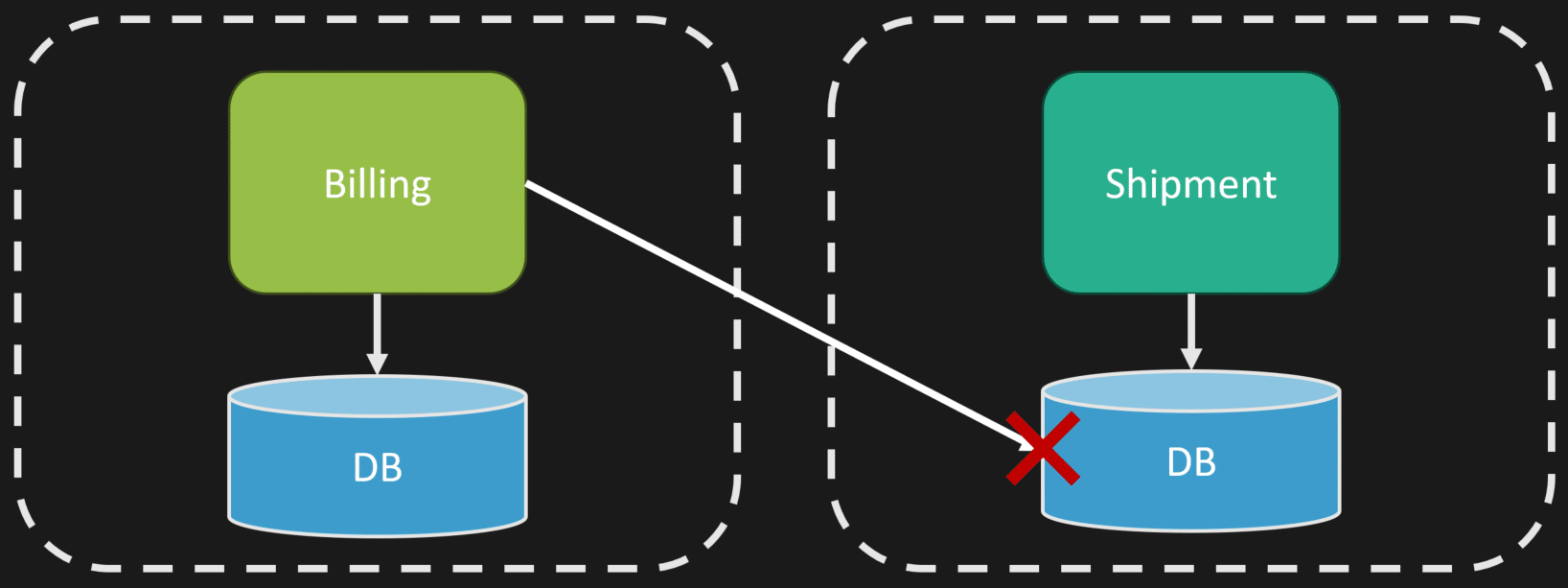
Imagine you have two different boundaries in your system — say billing and another boundary — and billing is reaching out and changing the state of the other boundary. This cannot happen. You need one particular boundary to be the authority that controls state changes. All state changes should always be valid, and your data should always be in a valid state.
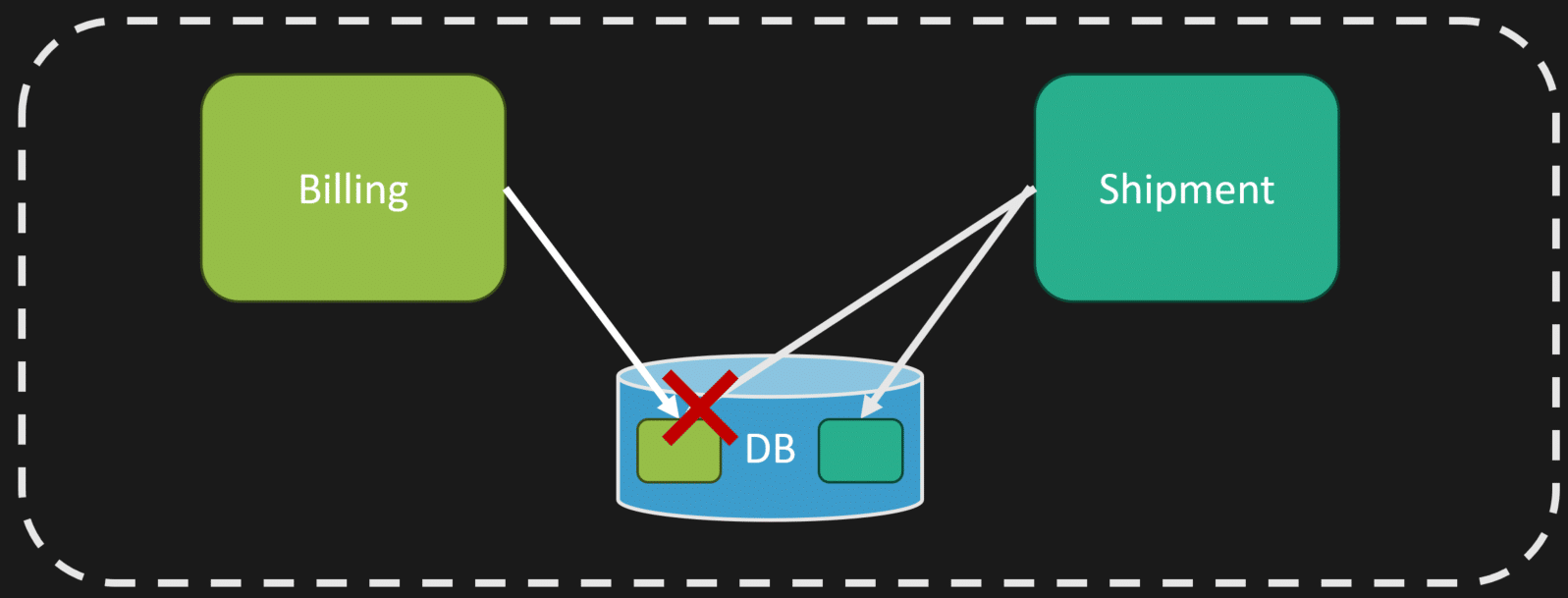
Even if you’re working in a monolith, the same principle applies. You need ownership of what controls the state. It can’t be a free-for-all where any part of your monolith can change any state anywhere in the system.
If you’ve ever been in a situation where you ask, “How did we get into this state? Why does the data even look like this? How did that happen?” and you have no idea, it’s because you have no ownership. Maybe someone manually connected to the database, or another service or application integrated and changed the state. Who knows? Without ownership, it’s a nightmare to deal with.
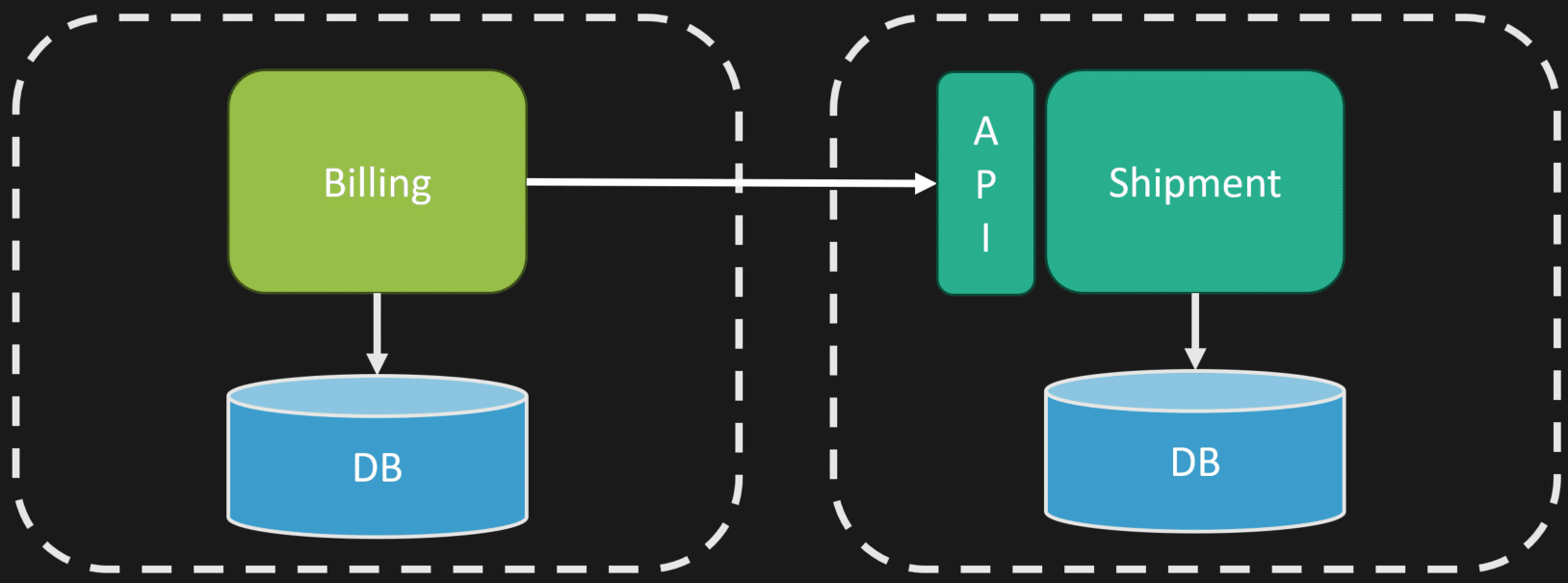
The solution is to define ownership explicitly. Define an API that other parts of your system interact with — this is the contract. When you want to make a state change, you invoke this API, and it’s the one controlling the change. There’s one specific place responsible for state changes.
What we’re really doing here is defining commands and queries. Both are equally important:
- Commands: Invocations that make state changes.
- Queries: Requests to get data related to a particular part of the system.
Every interaction funnels through one place that has ownership over commands and queries — it’s not a free-for-all.
2. Codebase Not Being Explicit
The second mistake is that your codebase is often too implicit. It’s typically driven by CRUD — create, read, update, delete — on entities. If you look at the codebase, can you really tell what it does and what its capabilities are? Usually not, because the workflows driven by end users aren’t captured explicitly.
Let me illustrate with an example using an event. In large systems, you add functionality over time and often want to be reactionary, so events help demonstrate this.
Say you have a shipment, and one of the things that needs to happen is the driver picking up the package. When the driver does that, you often assign a bill of lading (BOL). If you’re just using CRUD, you might update the shipment with the BOL. Then there’s an event that says, “The shipment changed.”
But why did the shipment change? You don’t know. Did someone enter the BOL for the first time? Did they re-enter it? Or did the pickup happen?
This is a big difference between implicit and explicit. Instead of a generic “shipment changed” event, you want an explicit event like “pickup stop loaded,” which includes shipment ID, stop, date, time, and the bill of lading. This is far clearer and tells you exactly what happened.
When your API is just “update shipment,” you don’t know what the user is actually trying to do. You’re left trying to infer or imply what the data change means and what you want to do after. But often, it’s not just that data changed — it’s why it changed.
Being explicit makes navigating your codebase much easier. And here’s the connection to the first mistake: if you have explicit commands, those commands are responsible for ownership and ensuring the state is valid.
3. Adding Indirection Without Realizing It
The third mistake is not realizing when you’re adding indirection, thinking it’s a good thing because of single responsibility, but it’s actually not.

Indirection happens when you have a caller that calls a target, but you add something in between, thinking it’s more focused and responsible. A common example is data access.

In reality, what looks simple, like a controller calling a data access layer, is often much more complex. You might have a controller calling a service, which calls another service, which uses a helper method, which finally calls an ORM that hits the database.
This kind of indirection is often invisible but makes requests hard to trace. The mistake is not being aware of the indirection you’re adding and whether it actually provides value.
Take abstractions, for example. If your calling code is highly coupled to an abstraction you created just to hide a third-party dependency, that can be valid if you have multiple implementations or want to simplify the API. But if the abstraction is only used in one place and serves no real purpose, it’s a useless abstraction.
Useless abstractions make your code harder to navigate and maintain. Sometimes, you’re better off managing the coupling directly rather than creating unnecessary layers.
The key here is to be mindful of the indirection you add and whether it truly adds value.
I’m not saying indirection is bad; it is not. Useless indirection and abstractions that serve no value, but are created because they are perceived as “clean,” are harmful.
4. Playing the “What If” Game
The fourth mistake is playing the “what if” game — thinking about all the possible future scenarios and trying to build your code to handle them upfront.
This is often a violation of the YAGNI principle (You Aren’t Gonna Need It). On the feature side, you might think, “What if someone asks for a similar but slightly different feature?” But if nobody has asked for it yet, how do you know it’s valuable?
On the technical side, you might write code that’s extremely generic or build in abstractions for hypothetical future changes — like swapping out technology — that may never happen.
This leads to in-house frameworks or generic code nobody understands or needs because there’s only one real use case.
I’m not saying you shouldn’t evolve your system or architecture. You should, and there are ways to do that without playing “what if.” I have a video about giving yourself options to evolve your system at low cost, which is a better approach.
The problem with “what if” is the cost of ownership. It’s not just the initial development cost but the ongoing maintenance and dealing with code that nobody uses and that adds complexity.
5. Not Managing Workflows Properly
The last mistake is not managing workflows effectively. This is a bit more advanced but important once you get past identifying explicit operations.

Think about a simple workflow like placing an order. You go through checkout, place the order, process payment, and then send a confirmation email. Seems straightforward.
The problem is when you treat this as one long procedural process rather than a workflow with isolated steps.

What happens if charging the credit card fails? How does your code handle that? Do you cancel the order? Send an email? Show an error in the UI?
If your code is very procedural, you likely have a tangled mess of conditions and exception handling that’s hard to follow and maintain.
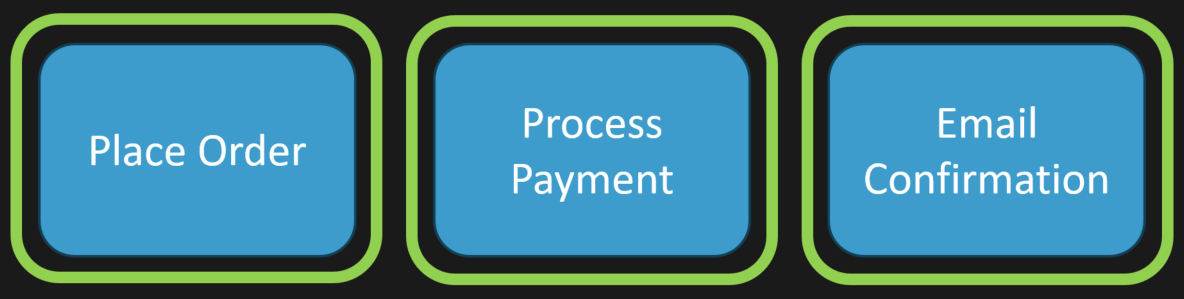
Workflows should be thought of as small units that execute in isolation and flow from one step to the next. Managing workflows this way makes handling errors, retries, and branching much cleaner.
Using tools like messaging, queues, and workflow engines can help you manage this complexity. I have several videos on messaging that dive into this topic.
The key takeaway is to recognize when you have workflows and use appropriate tools rather than building complicated procedural code with lots of branching logic.
Code that is Unmaintainable
From my experience building large business systems, these five mistakes come up often — and I’ve made some of them myself. They are:
- Allowing invalid state and lacking ownership of state changes.
- Having an implicit codebase driven by CRUD instead of explicit commands and queries.
- Adding unnecessary indirection that doesn’t add real value.
- Playing the “what if” game and building for hypothetical future needs.
- Not properly managing workflows, leading to tangled procedural code.
Each of these mistakes makes your code harder to maintain and evolve over time. Defining ownership, being explicit about commands and queries, managing indirection carefully, avoiding premature generalization, and properly handling workflows will make your system much more manageable.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.